DevOps
Automated Intelligent Document Processing Architecture

AI Workspace for Diagrams & Collaboration
Get your team started in minutes
Sign up with your work email for seamless collaboration.
Organizations often face challenges in managing and extracting insights from vast
amounts of unstructured data contained in emails, PDFs, images, and scanned documents. The variety of formats,
document layouts, and text types complicates the extraction process for standard Optical Character Recognition
(OCR) technologies.
To
address these challenges, AWS offers connected, pre-trained
artificial
intelligence (AI) service APIs that enable organizations to
derive meaningful insights from document-based data sources. This blog post presents a cost-effective, scalable
automated intelligent document processing solution using Amazon Text.
Across various industries, customers encounter the following document management challenges:
To address these challenges, we developed an automated intelligent document processing solution centered on a Natural Language Processing (NLP) engine, which includes:
The solution leverages other AWS services to create a cost-effective, scalable architecture for document processing.
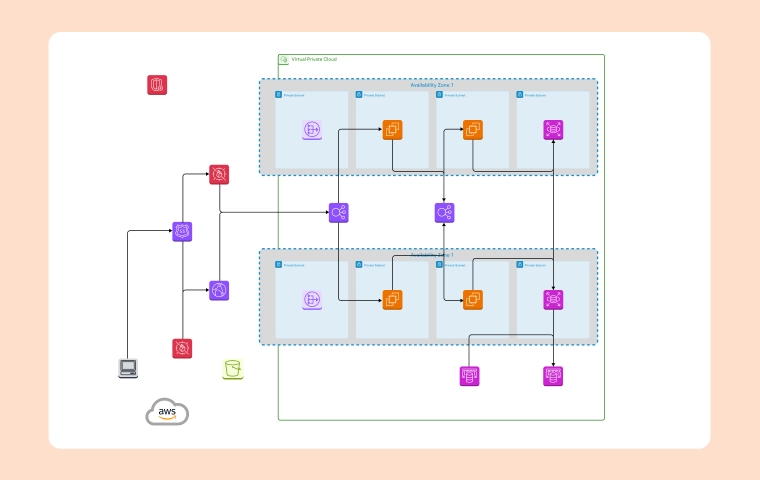
The automated intelligent document processing solution operates as follows:
Document Upload
Business users upload documents through a custom web application to a designated Amazon Simple Storage Service (Amazon S3) bucket.
Event-based Processing
An Amazon S3 event triggers an AWS Lambda function to start document pre-processing.
Pre-processing
The Lambda function evaluates the document payload, uses Amazon Simple Queue Service (Amazon SQS) for asynchronous processing, prepares document metadata, stores it in Amazon DynamoDB, and invokes the NLP engine for information extraction.
Text Extraction
The NLP engine uses Amazon Textract to extract text from various document types and optimizes API calls based on document metadata (e.g., form, tabular, or PDF).
Entity Parsing and Analysis
Amazon Comprehend processes the extracted text, performing entity parsing, sentiment analysis, and document classification. Custom classifiers within Amazon Comprehend enhance accuracy. PII data is masked using configurable rules.
Custom Parsing
A custom Python parser running in a Lambda function handles data from Microsoft Excel workbooks, invoked based on document metadata.
Machine Learning Integration
Output from Amazon Comprehend is fed into ML models deployed with Amazon SageMaker for additional use cases like recommendations, predictions, and personalization.
Post-processing
Upon job completion, another Lambda function updates the status in the Amazon SQS queue. The function parses the NLP engine’s output, augments data, validates key entities, assigns default values, and stores the results in Amazon DynamoDB and Amazon S3.
User Interface and Feedback
Users can review and compare extracted information with original documents via a custom UI, providing feedback to improve extraction and parsing accuracy. Amazon Cognito manages user authentication and authorization.
The automated intelligent document processing solution offers several benefits:
This solution is applicable across various industries:
Cloudairy Cloudchart empowers architects to visually design and collaboratively refine 3-tier AWS architectures. Drag-and-drop pre-built shapes for AWS services (ELB, EC2, RDS) simplify the visual representation. Real-time collaboration ensures everyone is on the same page, while annotations capture design choices and security considerations. This centralized documentation streamlines the design process for a well-defined and secure 3-tier AWS architecture.
Manual document processing is resource-intensive, time-consuming, and costly. It requires significant resources, reducing business agility and employee morale. Intelligent document processing automates the classification, extraction, and analysis of data, expediting decision cycles, reallocating resources to high-value tasks, and reducing costs.
AWS AI services' pre-trained APIs facilitate quick document classification, extraction, and analysis. This blog discussed the foundational architecture to accelerate the implementation of specific document processing use cases.
Start using Cloudairy to design diagrams, documents, and workflows instantly. Harness AI to brainstorm, plan, and build—all in one platform.
Table of Contents

Introduction
 Manage all your work in one placeCollaborate with your teamUse Cloudairy for FREE—forever
Manage all your work in one placeCollaborate with your teamUse Cloudairy for FREE—forever


 Related Articles
Related Articles

 – Design with Cloudairy Cloudchart.webp)