AWS
AWS Glue for Data Integration Elevating Architecture Design

AI Workspace for Diagrams & Collaboration
Get your team started in minutes
Sign up with your work email for seamless collaboration.
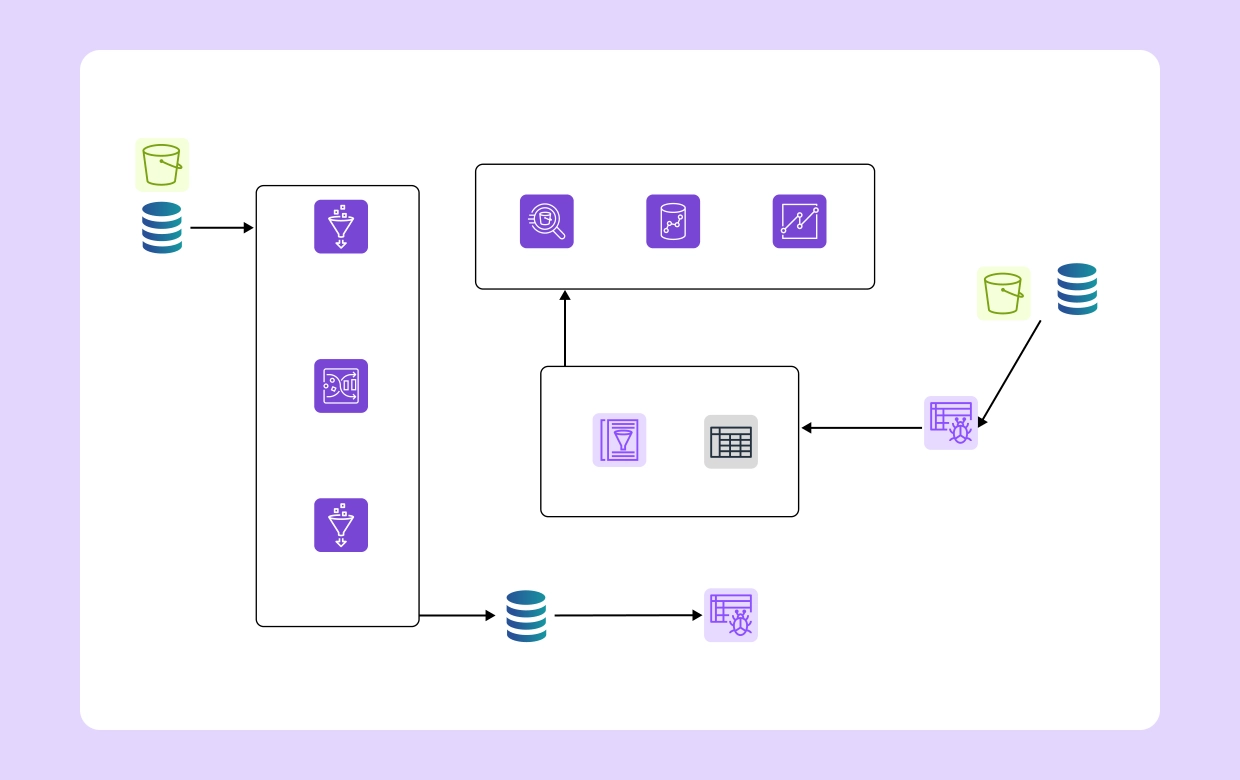
Data integration and ETL (Extract, Transform, Load) tasks can be complex, especially when working with massive datasets. AWS Glue, Amazon’s managed ETL service, simplifies the process, enabling users to prepare data for querying using other AWS services such as EMR or Redshift. However, optimizing the architecture design for data pipelines is crucial to unlocking AWS Glue's full potential. In this blog, we’ll explore how Cloudairy’s Cloudchart—a powerful tool for designing cloud architecture—can enhance how you build, visualize, and collaborate on your AWS Glue projects.
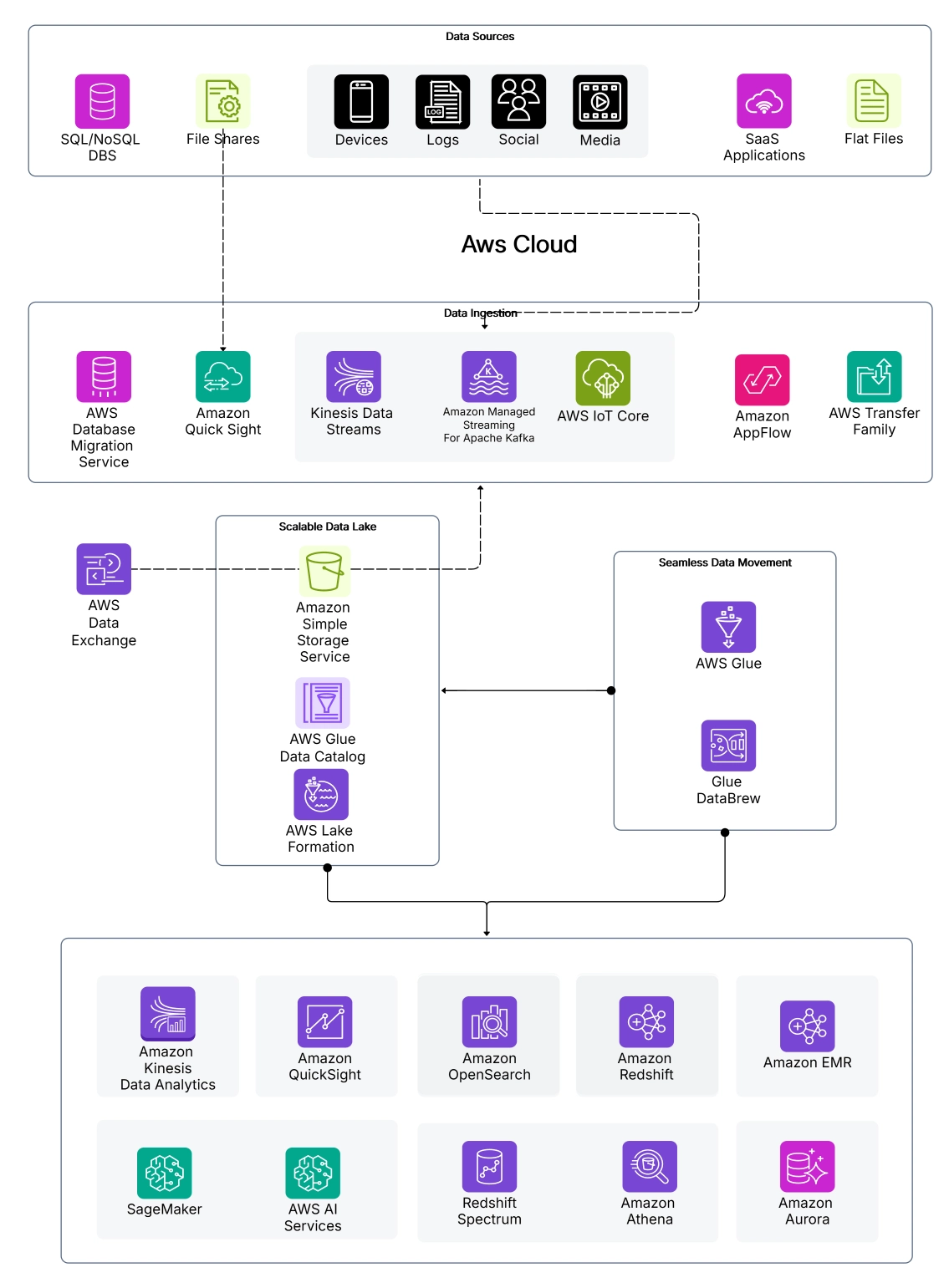
AWS Glue provides numerous features that make it highly effective for handling complex data integration tasks. These features are designed to automate various aspects of the ETL process, reducing manual effort while ensuring scalability and flexibility.
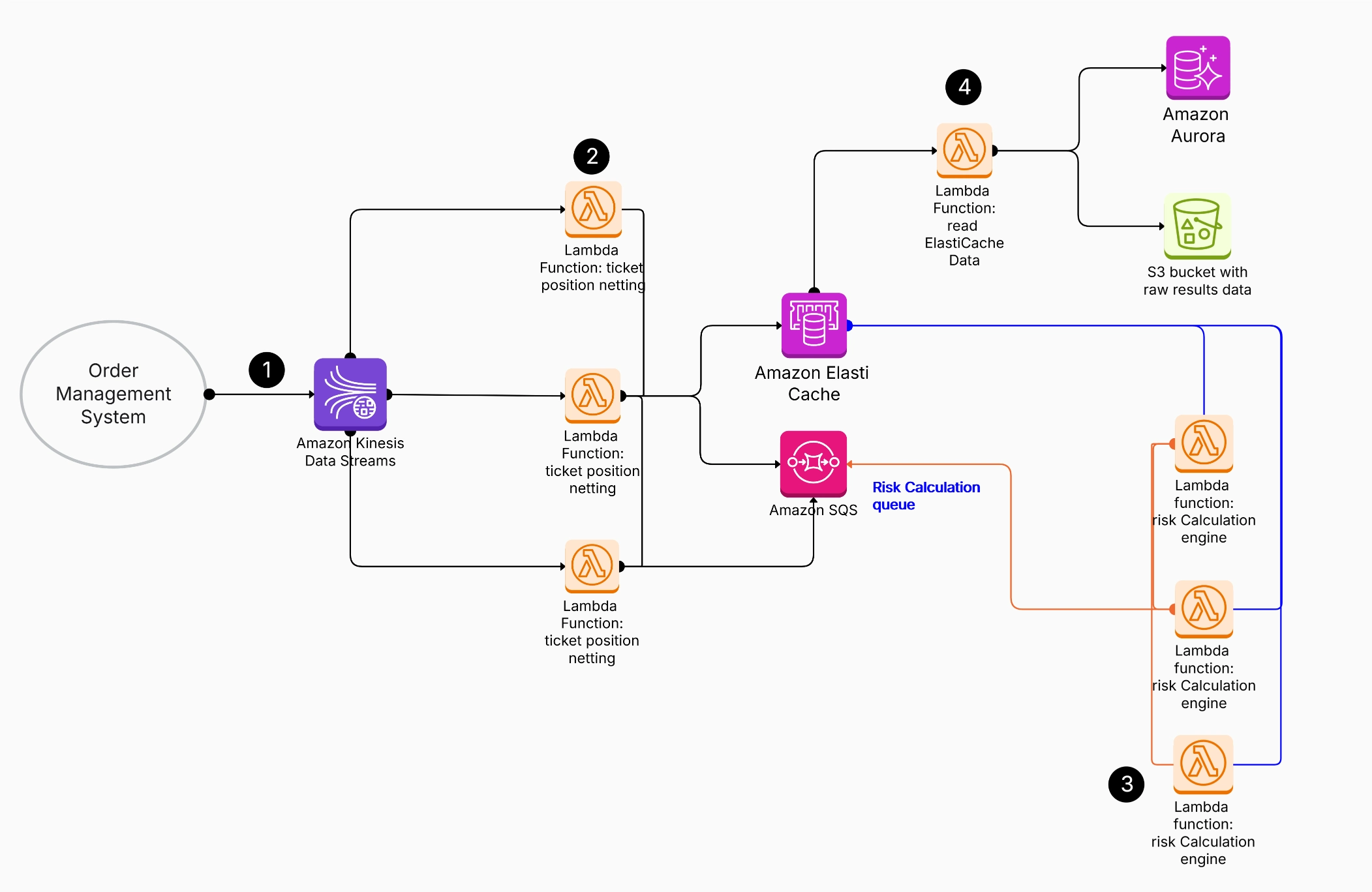
1. AWS Glue Data Catalog
2. Automatic ETL Code Generation
3. Automated Data Schema Recognition
4. Data Crawlers and Classifiers
5. Glue AWS Console
6. Job Scheduling System
7. ETL Operations with Customizable Code
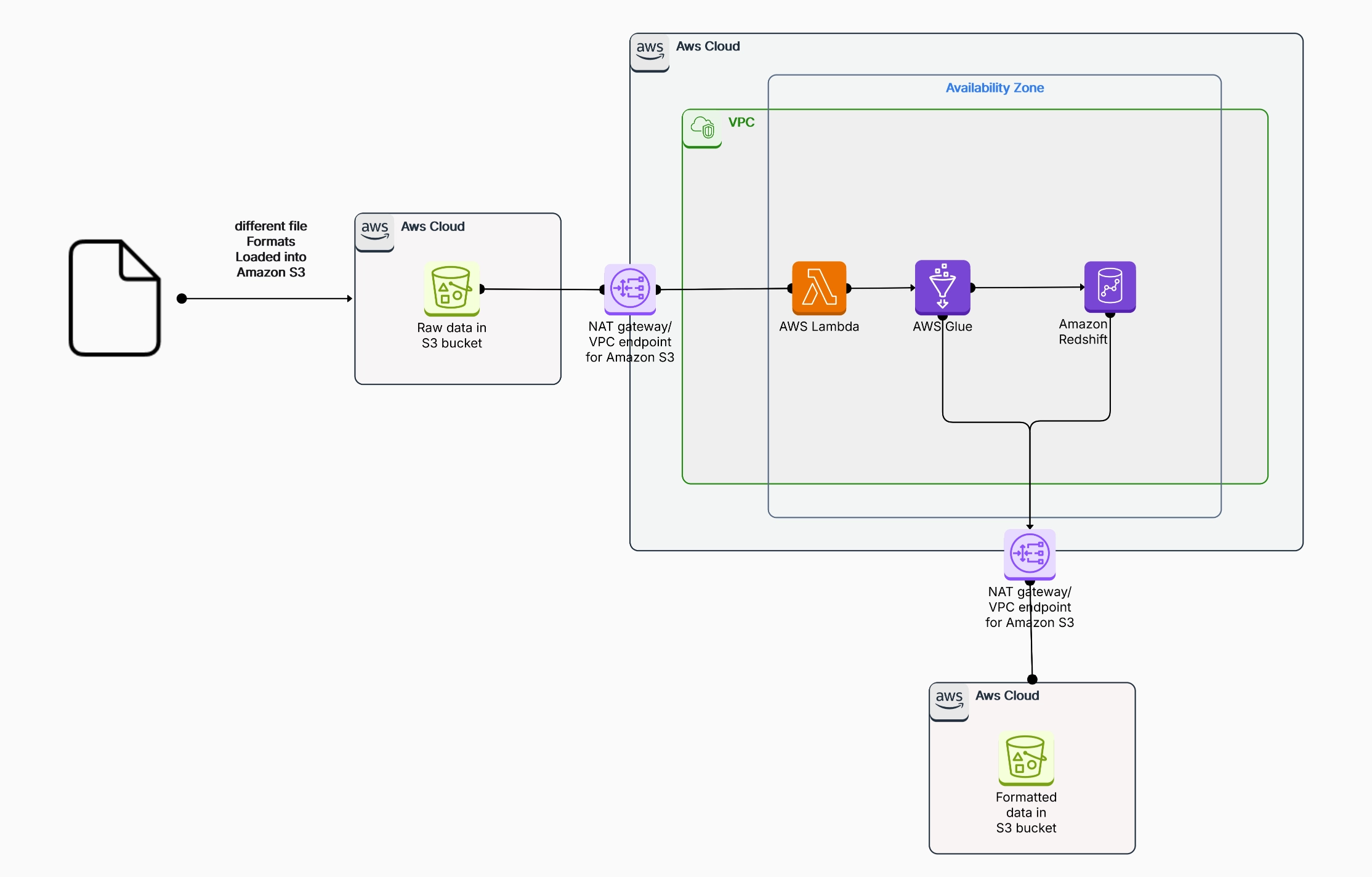
Amazon Web Services (AWS) Glue is a powerful ETL service that automates the data integration process. Still, its efficiency and scalability largely depend on how well you design the underlying data architecture. Here are the key reasons why thoughtful data architecture design is essential for AWS Glue:
1. Optimising Performance
A well-designed data architecture helps optimize the performance of your AWS Glue ETL pipelines. Efficiently structuring data flows, transformation steps, and resource management minimizes bottlenecks. Poorly designed architectures can result in slow performance, excessive resource usage, and higher costs.
2. Scalability
AWS Glue is built to handle large-scale data processing tasks, but scalability depends on the data architecture you implement. By carefully planning your architecture—organizing data partitions, optimizing joins, and handling schema evolution—you can ensure that your ETL processes scale seamlessly with growing data volumes.
3. Cost Efficiency
AWS Glue operates on a pay-as-you-go pricing model, where you are charged for the computing resources you use. A well-architected data solution can minimize unnecessary resource consumption. By reducing redundant data transformations, avoiding inefficient queries, and optimizing job execution, you can lower your costs significantly.
4. Handling Complex Workflows
Modern data environments often involve complex workflows, including batch and real-time data processing. AWS Glue can handle these tasks only if the architecture is designed to accommodate these complexities. A robust architecture ensures that batch processing and streaming data integration are handled separately and efficiently, reducing errors and ensuring data consistency.
5. Integration with Other AWS Services
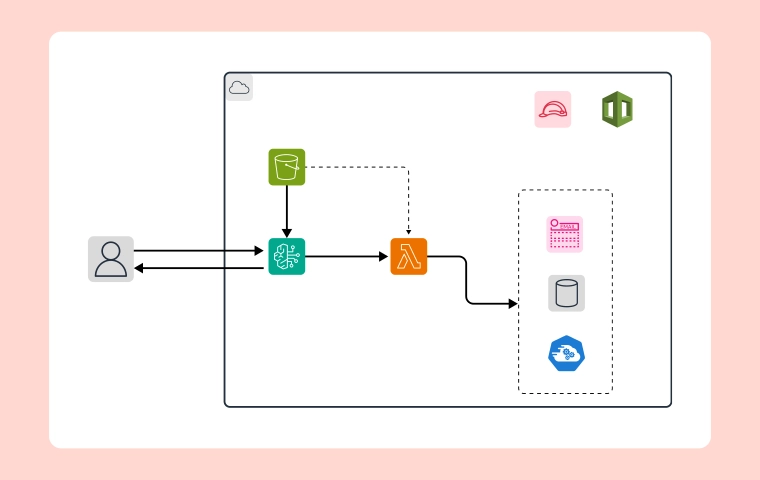
AWS Glue integrates seamlessly with other AWS services like Amazon S3, Redshift, and Kinesis, but proper architectural design is critical to leverage these integrations effectively. A well-designed architecture ensures smooth data flows between these services, enhancing the overall functionality of your data pipelines.
6. Data Governance and Compliance
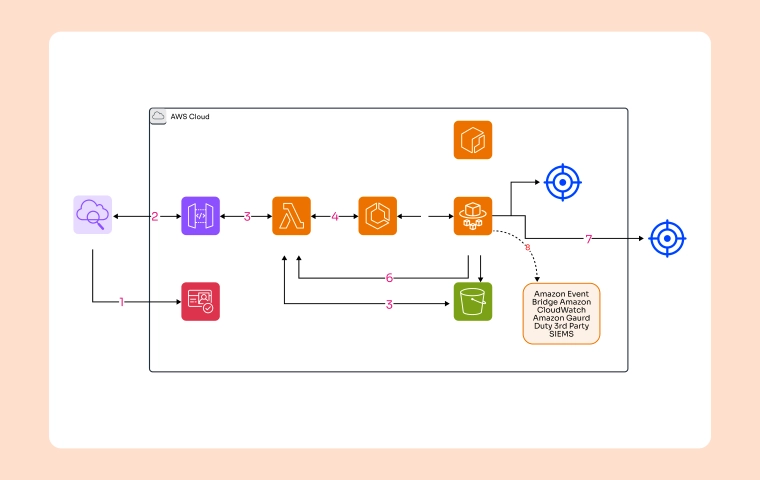
With increasing focus on data governance and compliance, it’s essential to design architectures that allow for easy data tracking, auditing, and management. AWS Glue supports features like AWS glue data catalogs and data versioning. Still, these features must be implemented through a sound architectural plan to maintain data integrity and adhere to regulatory requirements.
7. Error Handling and Recovery
Failures in ETL jobs are inevitable, but how you design the data architecture determines the ease of recovery. A strong design ensures robust error handling, automatic retries, and efficient logging, enabling AWS Glue to recover from failures without disrupting workflows. Poorly designed architectures can lead to frequent job failures and data consistency.
8. Security and Access Control
AWS Glue allows for fine-grained access control through AWS Identity and Access Management (IAM) policies, but designing a secure data architecture is crucial for maintaining security. By planning roles, permissions, and data encryption strategies upfront, you can ensure that sensitive data is protected and that only authorized users have access.
9. Future-Proofing Your ETL Workflows
A good data architecture is built with future scalability in mind. Adopting a flexible design that can accommodate new data sources, evolving schemas, and changing business requirements ensures that your AWS Glue setup remains adaptable to future needs without requiring a complete overhaul.
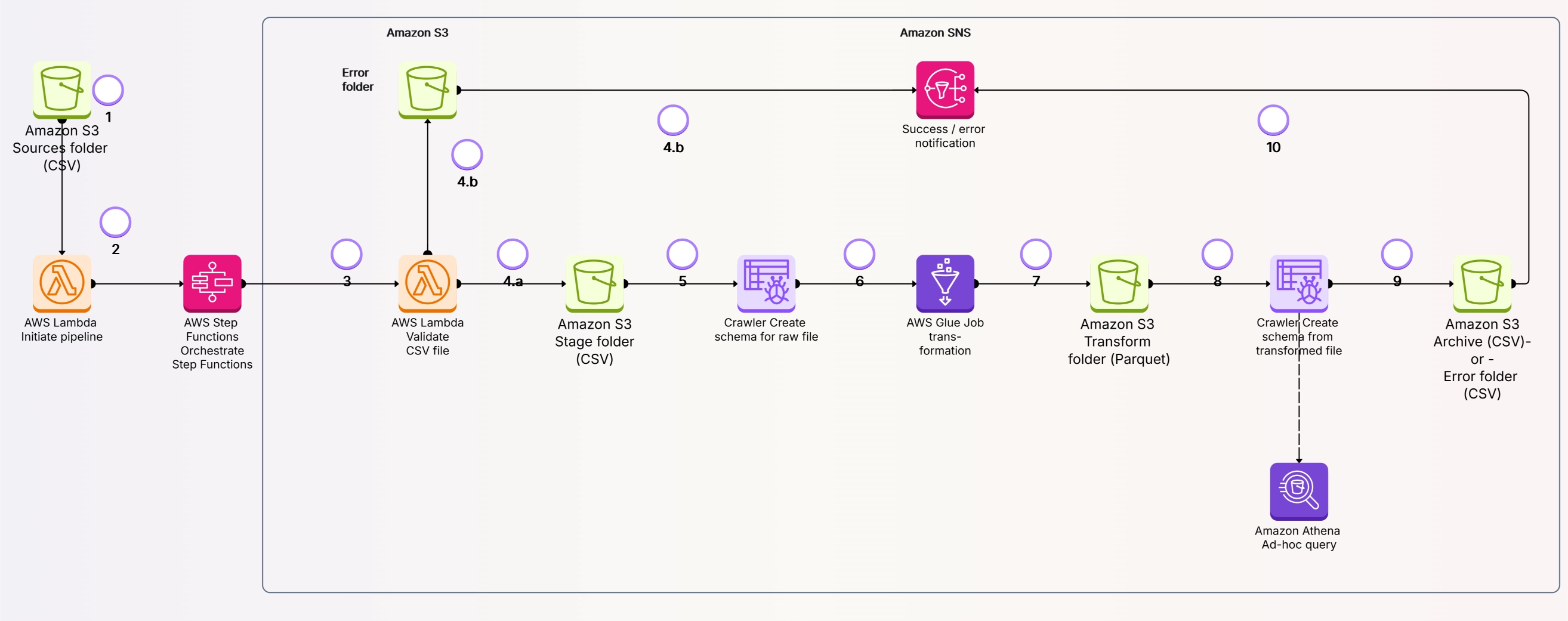
Here are the pros and cons overview:
Pros:
Cons:
This makes it overengineered for smaller projects or lightweight ETL jobs, where costs can also inflate due to unnecessary capabilities and complexity compared to simple ETL tools.
Hence, its pros and cons stand out in light of how great AWS Glue is for large-scale, serverless ETL jobs, but it also shows some significant challenges it might have, mainly for smaller or highly customized workflows.
1. Reliance on Apache Spark: AWS Glue relies heavily on Apache Spark to run ETL jobs, meaning users must be familiar with Spark to customize their ETL pipelines effectively.
The automatically generated code is either in Scala or Python, so developers need proficiency in these languages and a solid understanding of Spark's distributed computing framework.
This reliance can be a limitation for organizations that lack in-house expertise in Spark or need to onboard new developers quickly.
2. Inefficient High-Cardinality Joins: While Spark is powerful for many ETL operations, it struggles with high-cardinality joins—operations that involve combining datasets with many unique values.
These joins are critical for use cases like fraud detection or real-time analytics in advertising and gaming. To work around this limitation, engineers may need to employ additional databases or tools to manage intermediate data, which increases the complexity of ETL pipelines and adds overhead to system management
3. Complexity in Stream and Batch Processing: AWS Glue allows batch and stream processing, but handling these two paradigms together can be challenging. Glue requires separate pipelines for stream and batch processes, meaning that developers must write and optimize the same code twice while Cloudairy Cloudchart is designed to create cloud architecture, particularly for AWS Glue. While it helps streamline the design and collaboration phases, its purpose isn't optimization but enhancing how architecture is visualized and built. The standout feature, Generative AI Magic, enables users to describe their ideas in detail and instantly generate precise flowcharts, drastically reducing the time needed during the design phase of AWS Glue pipelines. This allows more focus on refining ETL processes. Another vital feature is real-time collaboration, which allows data engineers, architects, and stakeholders to work together on the same architecture diagram simultaneously, keeping everyone aligned and accelerating project timelines. Cloudairy Cloudchart focuses exclusively on cloud architecture design without handling direct optimizations.
In conclusion, a robust set of tools makes it a must-design AWS Gluearchitecture. Indeed, the AI-driven flowchart generator and the real-time collaboration functionality help bring complex ETL workflows to life, significantly saving time and eliminating errors.
Start using Cloudairy to design diagrams, documents, and workflows instantly. Harness AI to brainstorm, plan, and build—all in one platform.
Table of Contents

Introduction
 Manage all your work in one placeCollaborate with your teamUse Cloudairy for FREE—forever
Manage all your work in one placeCollaborate with your teamUse Cloudairy for FREE—forever


 Related Articles
Related Articles