AWS
Protecting Data and Complying with Regulations Architecture Designed with Cloudairy Cloudchart

AI Workspace for Diagrams & Collaboration
Get your team started in minutes
Sign up with your work email for seamless collaboration.
Financial companies process hundreds of thousands of documents daily, including loan and mortgage statements containing confidential customer information. Ensuring data privacy by redacting sensitive data is crucial for protecting both customers and institutions. Manually redacting digital and physical documents is time consuming and labour intensive, and the accidental release of personal information can be devastating.
In this blog, we will explore how a financial services organization can automatically redact personally identifiable information (PII) from its data using the machine learning (ML) capabilities of Amazon Comprehend and Amazon Athena. This approach helps comply with federal regulations and meet customer expectations.
1. Background
A financial services organization processes a vast number of documents daily, including loan applications, mortgage statements, and financial reports. These documents often contain PII, such as social security numbers, credit card information, and dates of birth.
2. Challenge
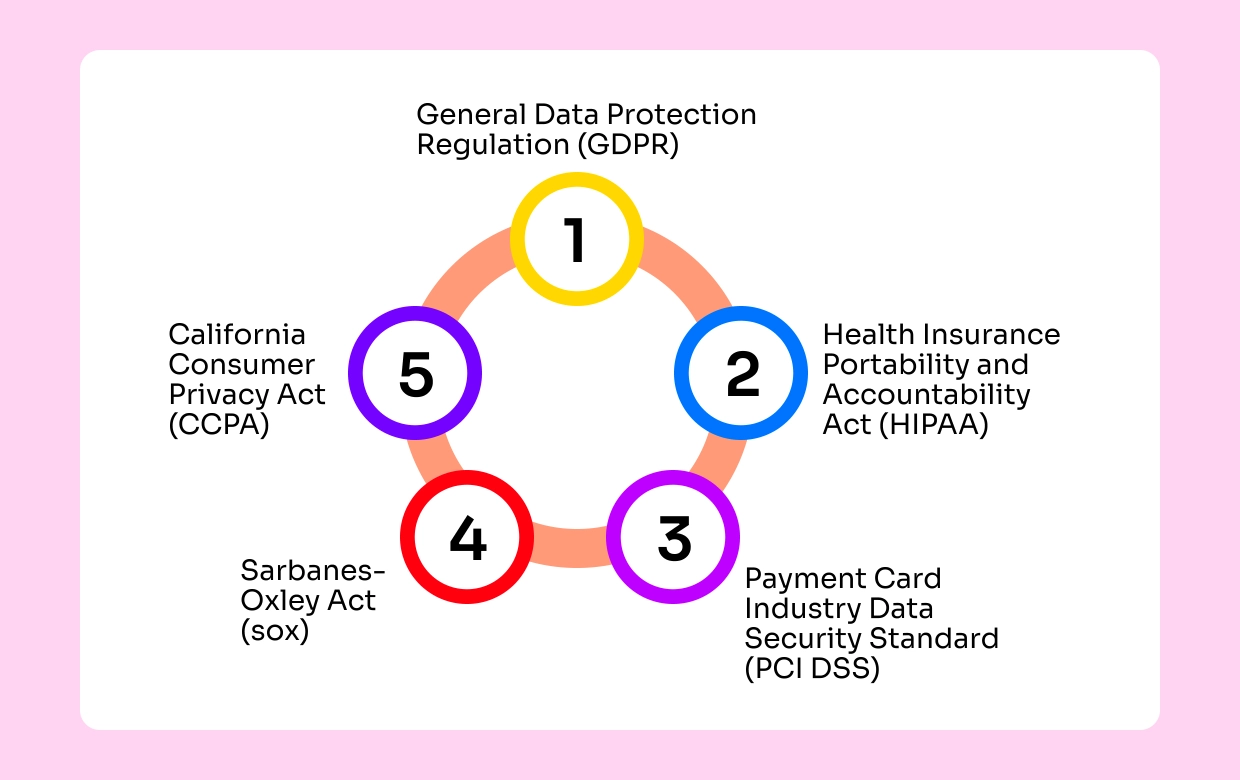
Manual redaction of PII is resource-intensive and prone to human error. The organization needs an automated solution to efficiently redact PII, ensuring compliance with regulations like the California Consumer Privacy Act (CCPA), Europe’s General Data Protection Regulation (GDPR), and Payment Card Industry Data Security Standards (PCI DSS).
3. Solution
Implementing an automated PII redaction process using AWS services like Amazon Comprehend and Amazon Athena, integrated into their existing ML pipeline.
Protecting PII is crucial for compliance with regulations such as the CCPA, GDPR, and PCI DSS. Below, we illustrate how sensitive structured and unstructured data stored in AWS data stores can be redacted before being made available for feature engineering and ML model building.
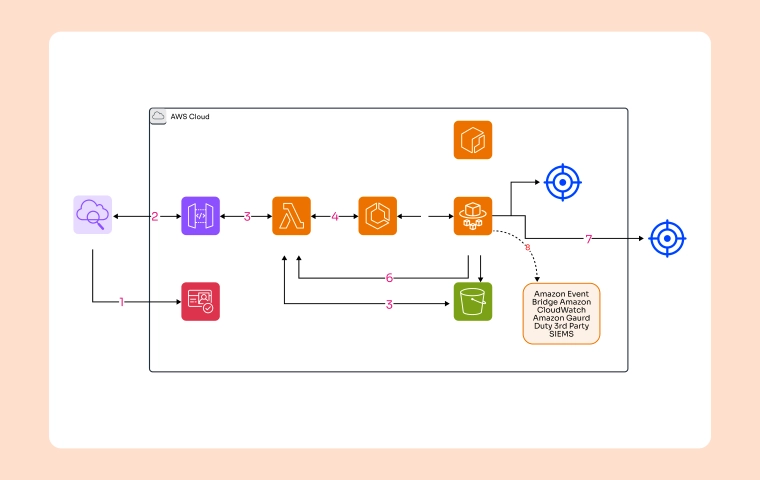
Architecture Walkthrough
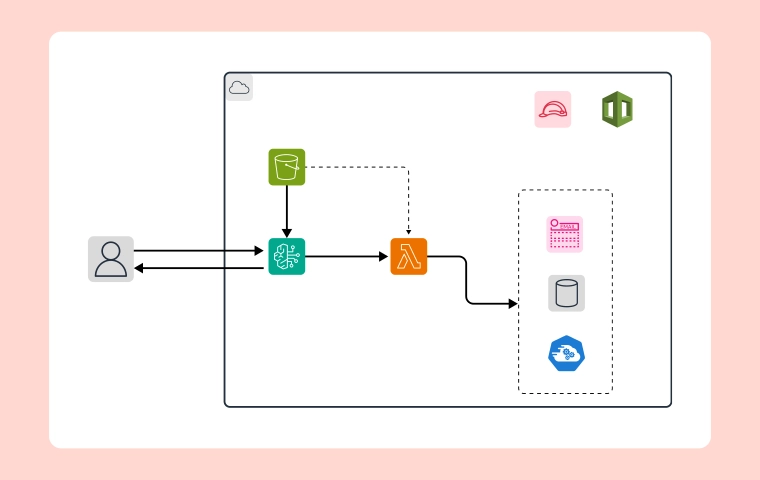
1. Data Ingestion
Using services like AWS DataSync, AWS Storage Gateway, and AWS Transfer Family, data is ingested into AWS in batch or streaming patterns. This data lands in an Amazon Simple Storage Service (Amazon S3) bucket, referred to as "raw data."
2. Detecting Sensitive Data
To detect sensitive data in the raw data bucket, the organization uses Amazon Macie. Macie is a fully managed data security and privacy service that uses ML and pattern matching to discover and protect sensitive data in AWS. When Macie discovers sensitive data, it tags the objects with an Amazon S3 object tag, identifying that sensitive data was found before progressing to the next stage of the pipeline.
3. Redacting Unstructured Data
The tagged data is moved to a "scanned data" bucket. Here, Amazon Comprehend, a natural language processing (NLP) service, uncovers information in unstructured data and redacts sensitive fields like credit card numbers, dates of birth, social security numbers, and passport numbers.
4. Conditional Redaction
For specific use cases, the organization uses Amazon S3 Object Lambda to redact data as it is requested. An AWS Lambda function intercepts each GET request, redacting data as necessary before returning it to the requestor. This allows maintaining a single copy of all data and redacting it only when needed.
5. Joining Multiple Datasets
To join datasets from different sources, the organization uses an Amazon Athena federated query. User-defined functions (UDFs) with Athena federated queries help redact data in Amazon S3 or from other sources, such as Amazon Relational Database Service (Amazon RDS), Amazon Redshift, or Amazon DocumentDB. UDFs enable custom processing like redacting sensitive data, compressing and decompressing data, or applying customized decryption.
6. Preparing Data for ML
Redacted data is stored in another S3 bucket, ready for ML pipeline consumption. Using AWS Glue DataBrew, data preparation can be done without writing any code. DataBrew offers reusable recipes from over 250 pre-built transformations, automating data preparation tasks.
7. Feature Engineering
Data is then used by Amazon SageMaker Data Wrangler for feature engineering on curated data. SageMaker Data Wrangler provides over 300 pre configured data transformations, enabling the organization to transform data effectively for models without writing code.
8. Storing Features
The output of SageMaker Data Wrangler jobs is stored in Amazon SageMaker Feature Store, a purpose built repository for storing and accessing features. SageMaker Feature Store provides a unified store for features during training and real-time inference, eliminating the need for additional code or manual processes to keep features consistent.
9. ML Model Training
The organization uses the ML features in SageMaker notebooks or SageMaker Studio for ML training on redacted data. SageMaker notebook instances run the Jupyter Notebook App, while SageMaker Studio is a web-based integrated development environment (IDE) for ML, enabling seamless building, training, debugging, deploying, and monitoring of ML models.
1. Compliance with Regulations
Automating PII redaction ensures compliance with various data protection regulations like CCPA, GDPR, and PCI DSS. By leveraging machine learning models and automated tools, financial services organizations can minimize the risk of non-compliance and avoid hefty fines and reputational damage.
2. Reduced Manual Effort
Manual redaction is time-consuming and error-prone. Automating the process with Amazon Comprehend drastically reduces the manual effort required and eliminates human errors, ensuring consistent and accurate redaction of sensitive data.
3. Enhanced Security
By integrating services like Amazon Macie, AWS Lambda, and Amazon S3 Object Lambda, organizations can identify and redact sensitive data in real-time, providing an additional layer of security. This reduces the risk of exposing confidential customer information.
4. Improved Efficiency and Scalability
The ability to automatically redact PII at scale using AWS services allows organizations to handle growing volumes of data without compromising on security or performance. This improves overall operational efficiency and enables seamless scaling.
5. Optimized Data for ML Models
Redacting sensitive data while maintaining the integrity of datasets ensures that anonymized data can be safely used for feature engineering and ML model building. This results in more accurate and compliant models.
1. Define a Comprehensive Data Governance Policy
Establish a data governance policy that defines how PII should be handled, including redaction guidelines, access control, and retention policies.
2. Leverage a Centralized Tagging Strategy
Consistent tagging of sensitive data across different AWS services helps identify and manage PII effectively. Use AWS Organizations to enforce tagging policies centrally.
3. Integrate Security and Compliance Monitoring
Regularly monitor and audit your data security posture using services like AWS Security Hub and Amazon Macie. Automate remediation using AWS Lambda.
4. Use Conditional Redaction for Specific Use Cases
Implement conditional redaction using Amazon S3 Object Lambda, enabling data redaction only when requested. This minimizes the need to maintain multiple copies of redacted data.
5. Automate Data Preparation and Feature Engineering
Utilize AWS Glue DataBrew and Amazon SageMaker Data Wrangler for code-free data preparation and feature engineering. Automate these processes through AWS Glue workflows and SageMaker pipelines.
6. Continuously Improve Your Redaction Models
Regularly update your machine learning models used for PII detection with Amazon Comprehend. Incorporate feedback loops to fine-tune redaction accuracy.
By leveraging AWS services such as Amazon Macie, Amazon Comprehend, Amazon S3 Object Lambda, Amazon Athena, AWS Glue DataBrew, and Amazon SageMaker, a financial services organization can automate the redaction of PII, ensuring data privacy and compliance with regulatory requirements. This automated approach not only enhances data security but also improves operational efficiency by reducing the likelihood of data breaches and freeing up valuable resources.
Implementing an automated PII redaction process is crucial for meeting customer expectations and staying compliant with ever-evolving data protection regulations. The solution outlined here provides a robust framework for protecting sensitive data while enabling financial organizations to harness the power of machine learning effectively.
Key Takeaways:
By adopting these practices and leveraging the power of AWS's machine learning capabilities, financial organizations can confidently protect their customers' data while driving innovation and compliance in their data pipelines.
Cloudairy streamlines cloud architecture design through Cloudchart, its real-time collaborative visual workspace. Cloudchart empowers architects to brainstorm and design intricate cloud architectures using pre built components and intuitive features. This fosters clear communication and ensures all stakeholders have a unified view of the architecture being designed.
Start using Cloudairy to design diagrams, documents, and workflows instantly. Harness AI to brainstorm, plan, and build—all in one platform.
Table of Contents

Introduction
 Manage all your work in one placeCollaborate with your teamUse Cloudairy for FREE—forever
Manage all your work in one placeCollaborate with your teamUse Cloudairy for FREE—forever


 Related Articles
Related Articles