WorkHub
- Home
-
Cloudairy Al
- Pricing
- Book a Demo
Whiteboard
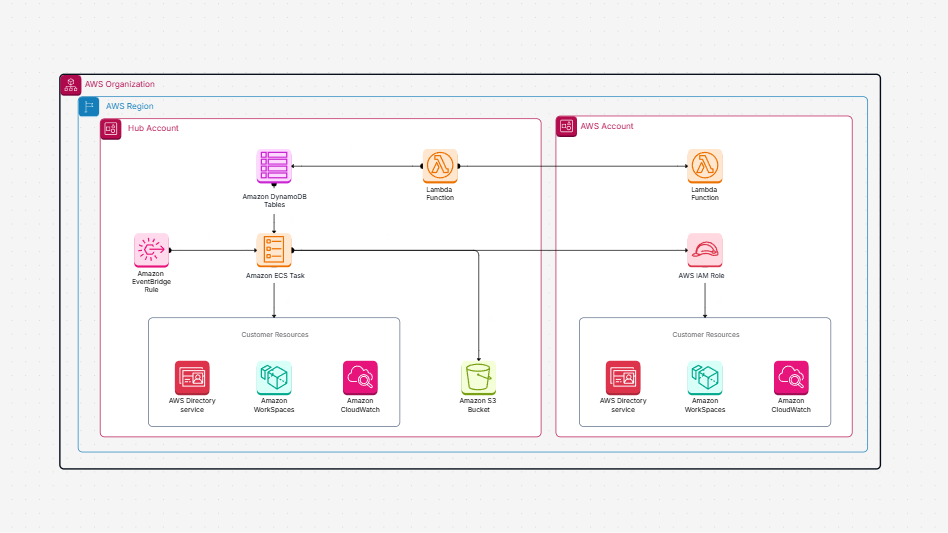
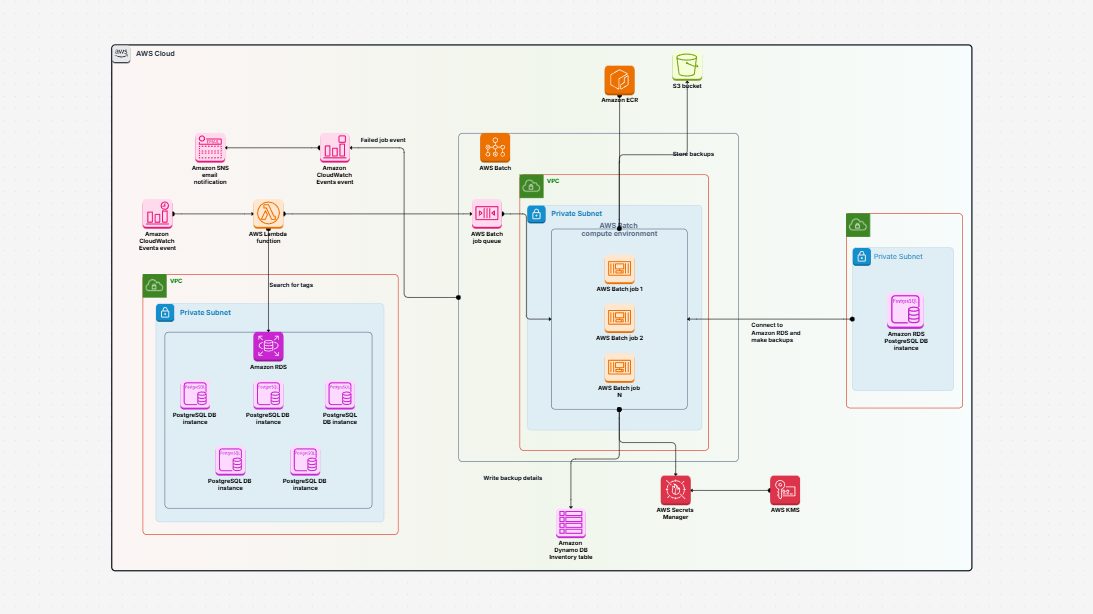
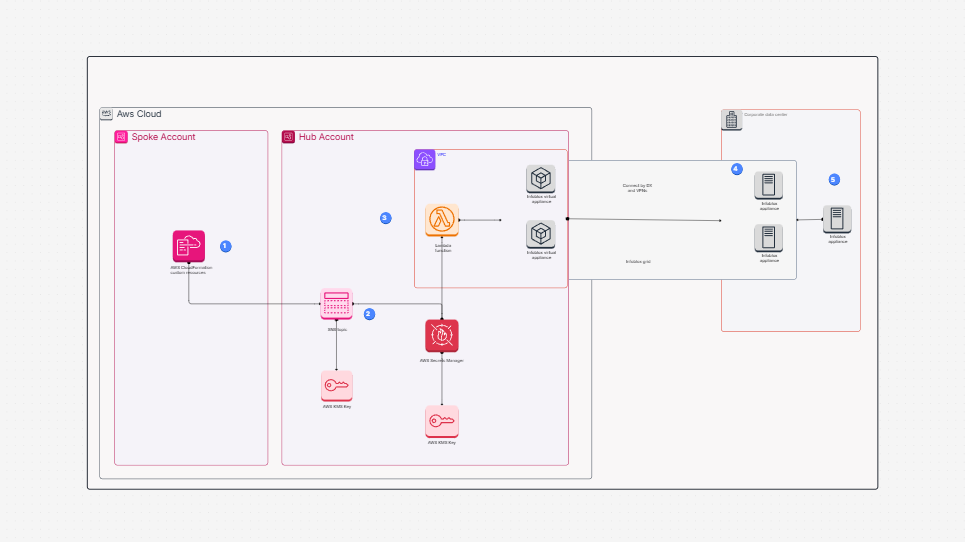
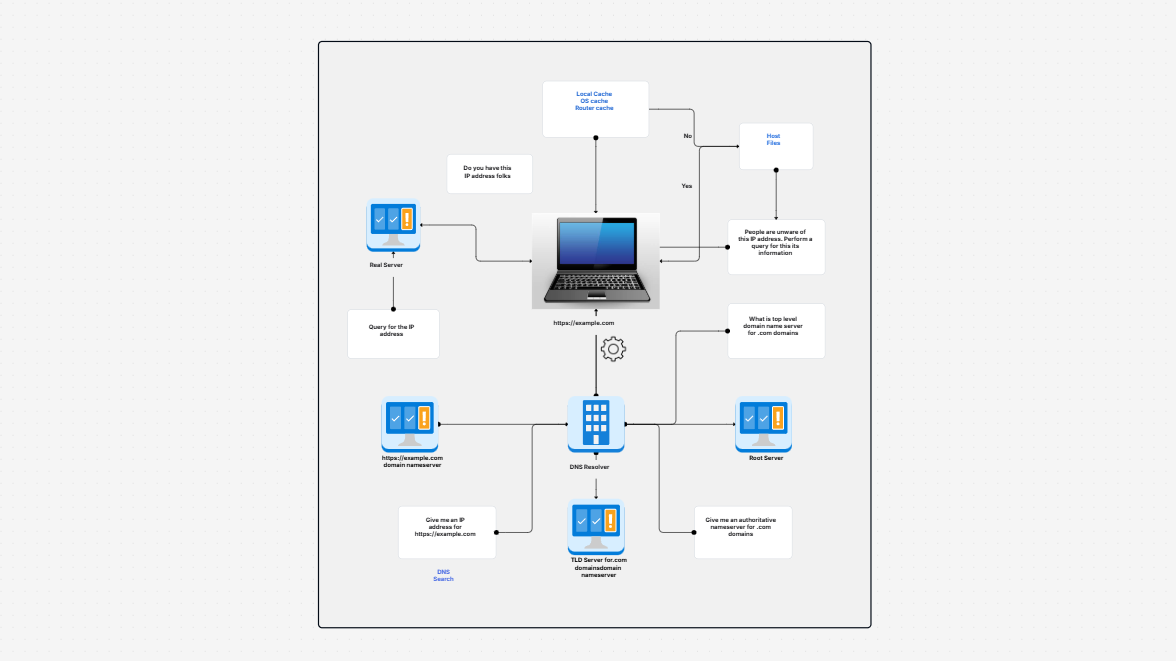
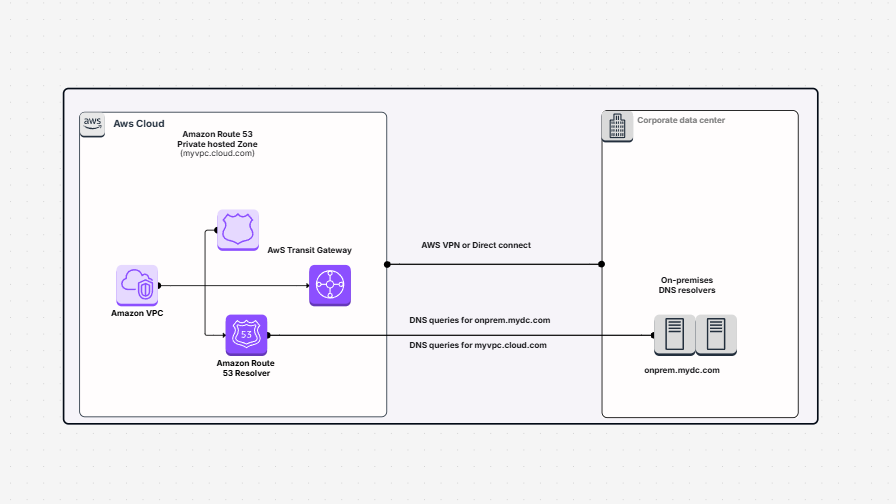
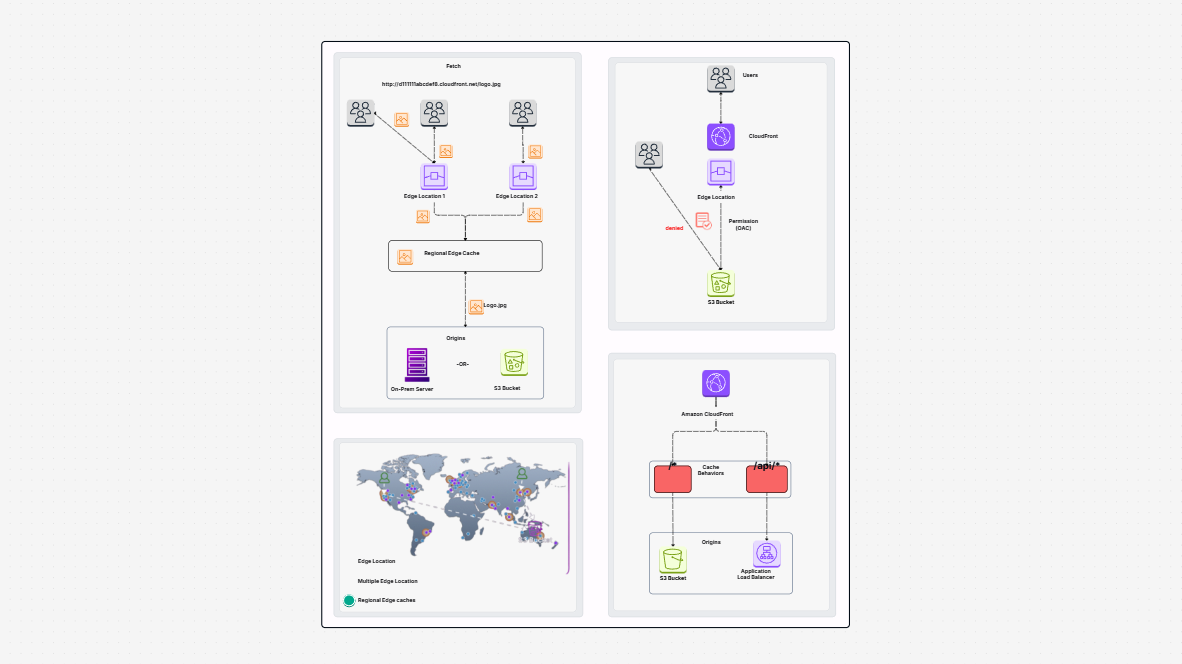
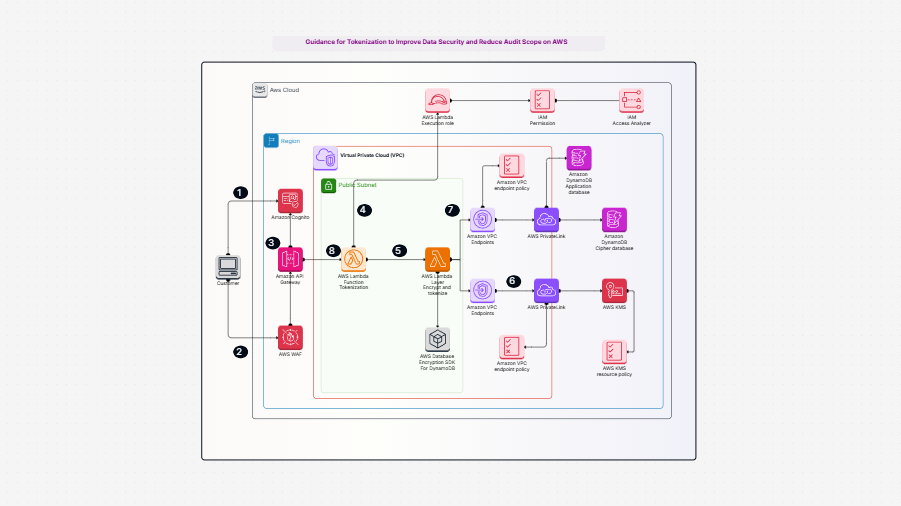
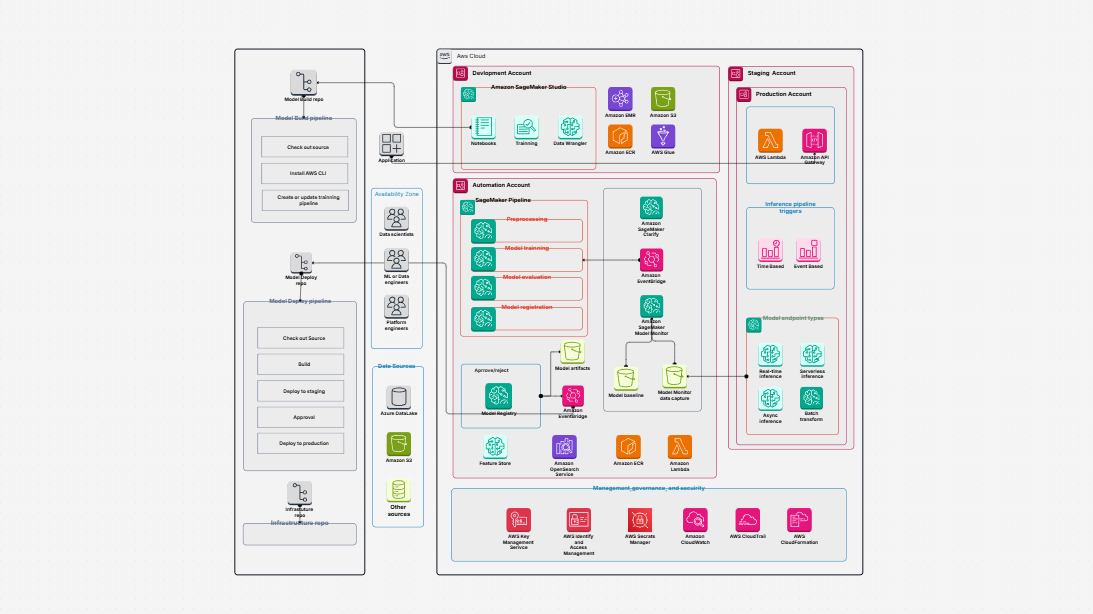
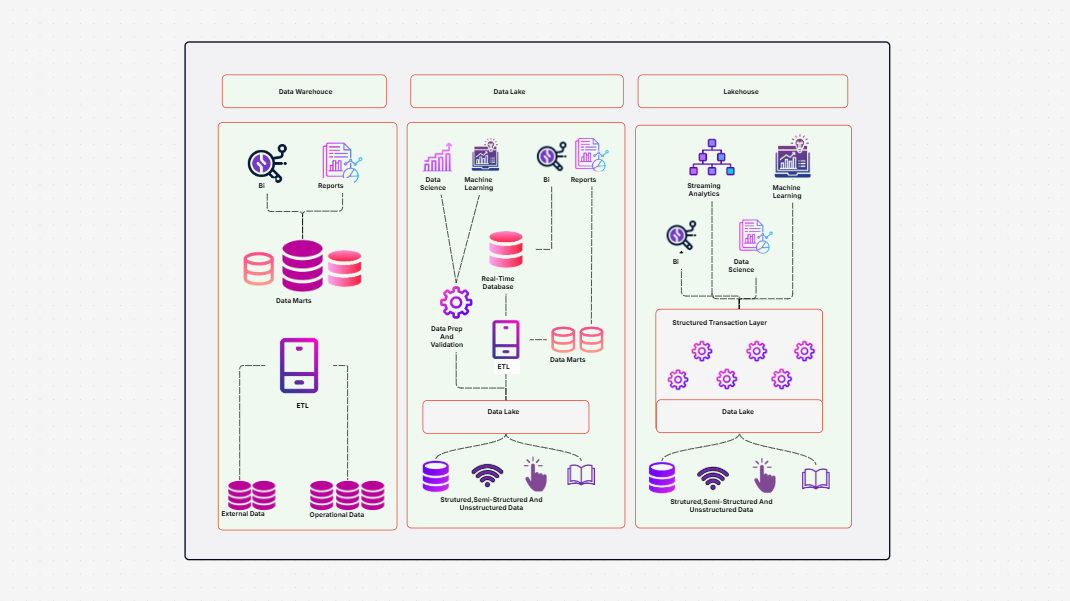
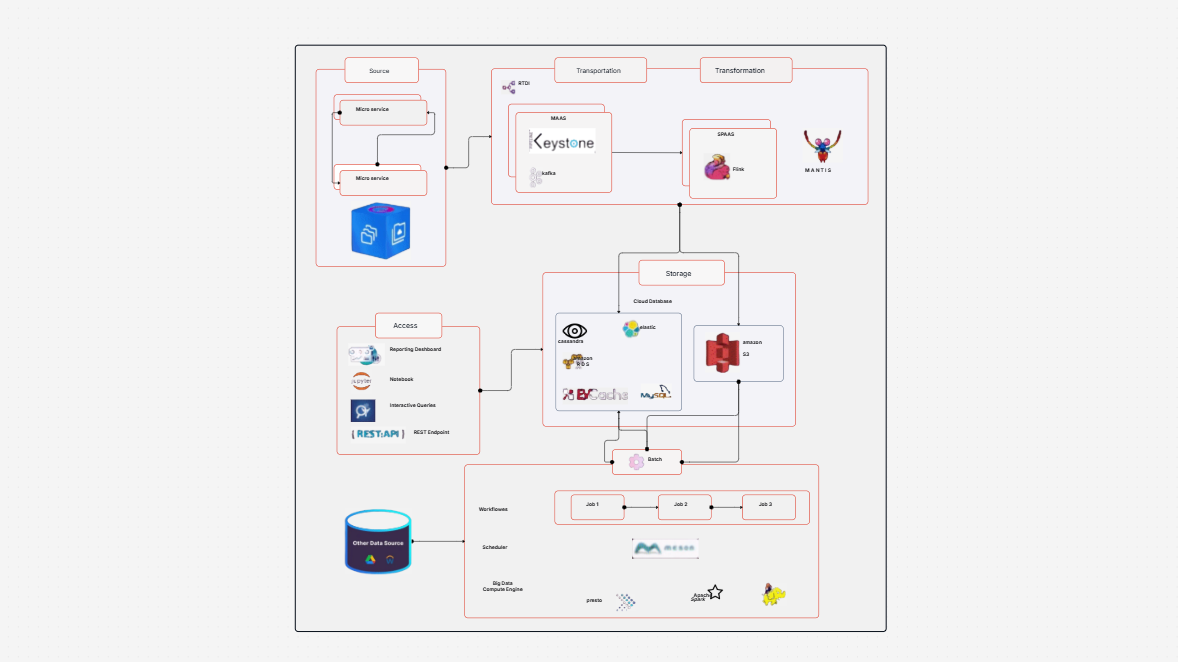
Need a better way to plan and manage how your data flows in AWS? Designing a data pipeline process in the cloud can be complex—especially when it involves multiple AWS services and accounts. That’s where the AWS Data Pipeline Process Template helps. It gives you a clear, visual way to map out your cloud data pipeline—from data generation to transformation and analysis—using the best tools in the AWS ecosystem.
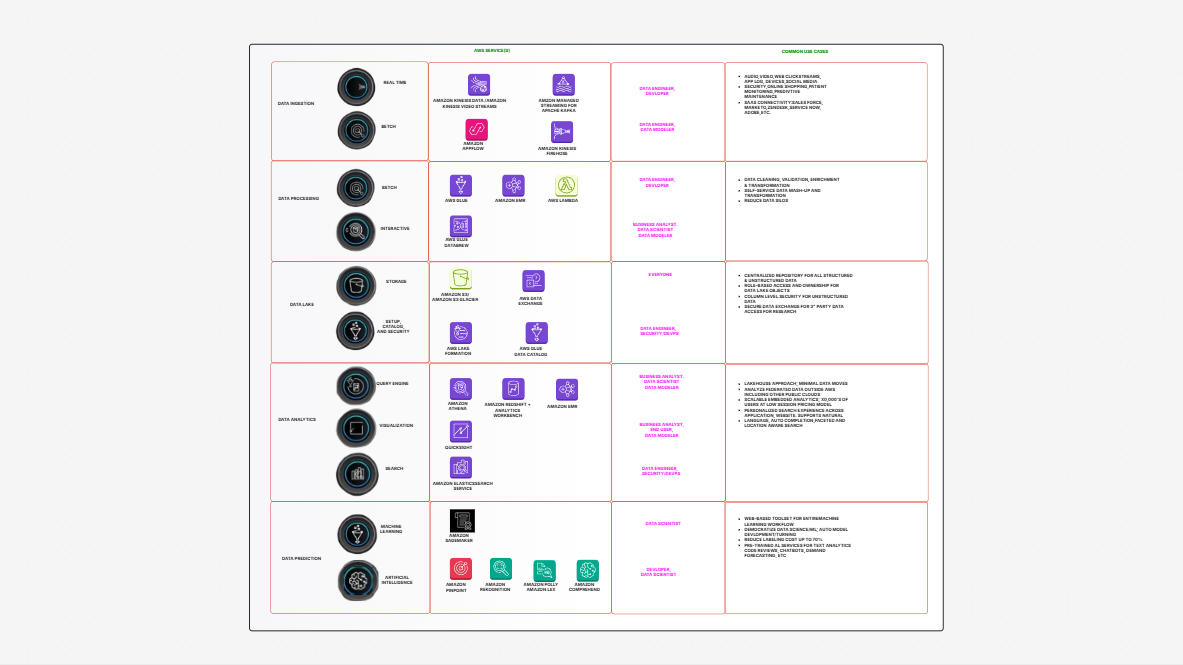
The AWS Data Pipeline Process Template offers a complete framework to design, visualize, and manage your cloud-based data workflows. It shows how data is:
This template helps you build a clear diagram of your automated data pipeline on AWS, showing every step from ingestion to analysis.
Using this template, you can:
Whether you're starting fresh or improving an existing setup, this template gives you everything you need to manage your AWS Data Pipeline more effectively.
Creating reliable and scalable AWS data pipelines can be a challenge—but with the right tools, it becomes much easier. Cloudairy’s AWS Data Pipeline Process Template helps you plan, design, and visualize every step of your automated data pipeline on AWS. This template outlines the AWS Data Pipeline Process clearly, so you can streamline execution and ensure consistency.
Whether you're building a new pipeline or improving an existing cloud data pipeline, this template brings clarity to your workflow. It’s all about helping your teams stay perfectly aligned, avoid errors, and scale with confidence using a structured AWS Data Pipeline Process.
If you are looking for a straightforward, flexible way to build and manage your AWS data workflows, this is the perfect place to start. You’ll have a reliable framework based on proven practices in the AWS Data Pipeline Process.
Find templates tailored to your specific needs. Whether you’re designing diagrams, planning projects, or brainstorming ideas, explore related templates to streamline your workflow and inspire creativity
Unlock AI-driven design and teamwork. Start your free trial today










Unlock AI-driven design and teamwork. Start your free trial today