WorkHub
- Home
-
Cloudairy Al
- Pricing
- Book a Demo
Whiteboard
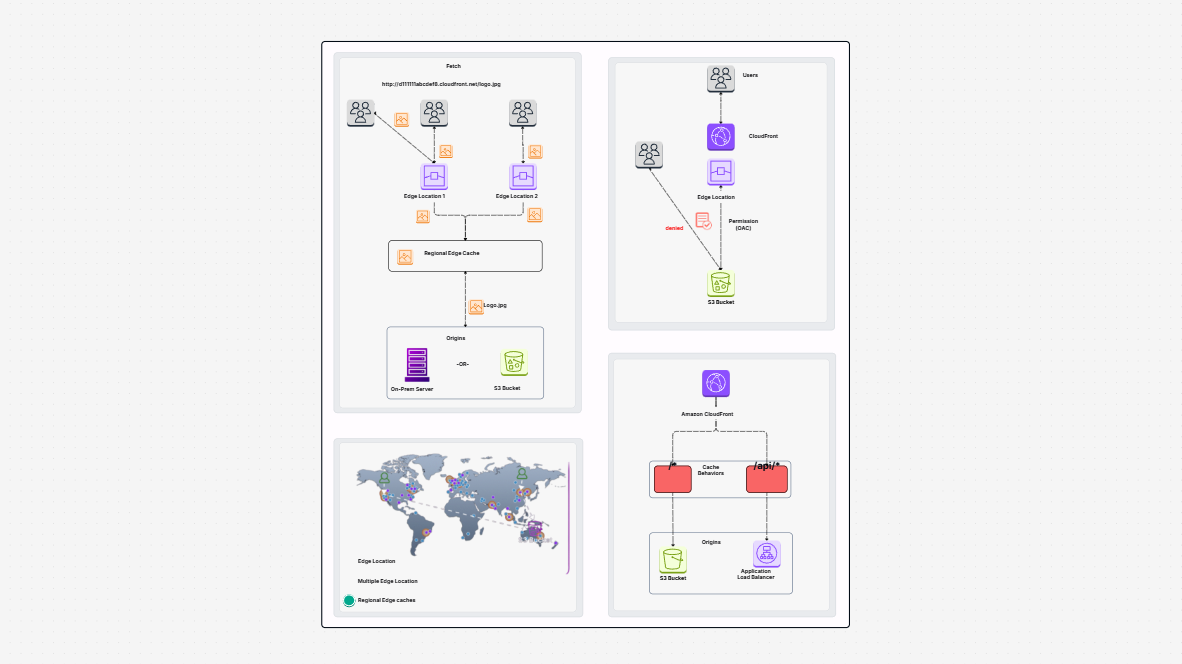
Have you ever considered how companies refresh their information without moving everything over and over again? Suppose you have a bucket with many thousands of files, and you are adding some new files every day. Rather than migrate all of them every day, would it not be more efficient to migrate just the new ones? That is just the type of problem this template addresses.
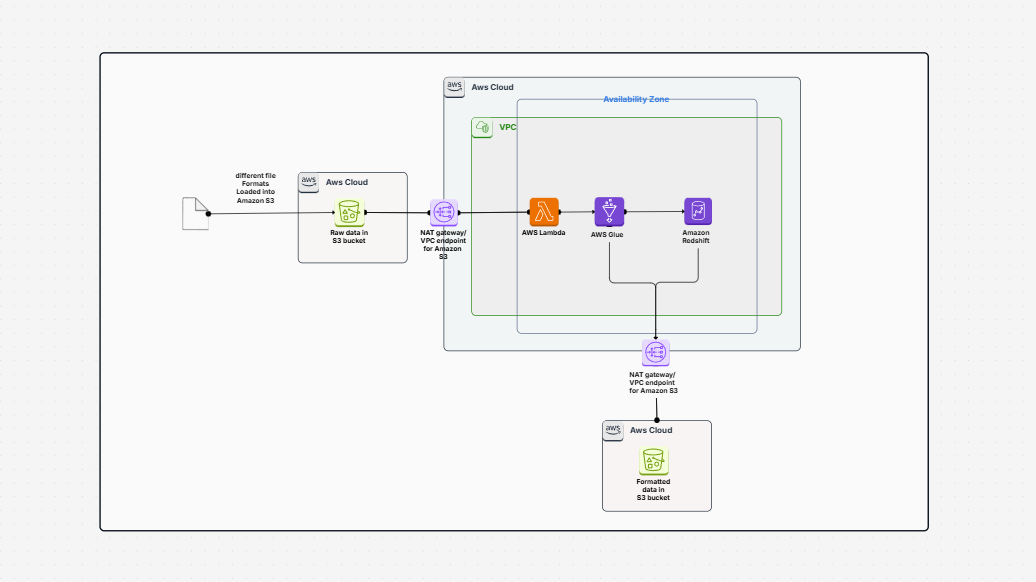
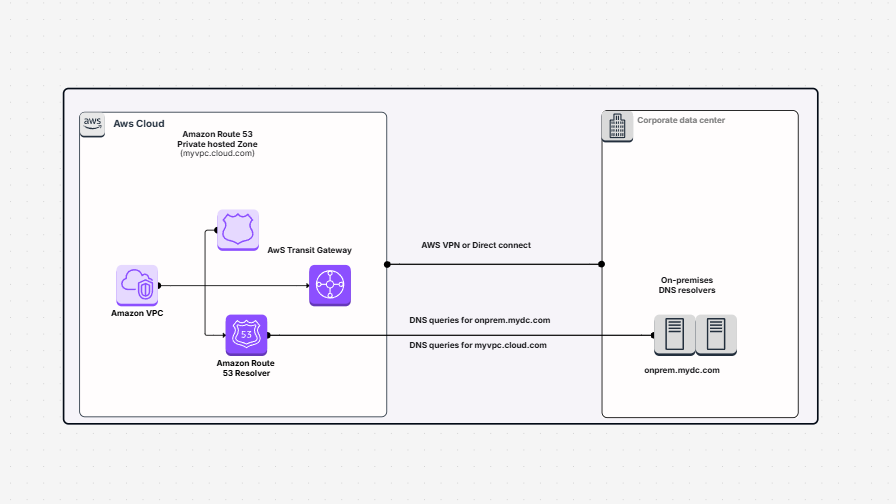
The Incremental ETL Pipeline with AWS Glue template shows how to create an incremental ETL pipeline with AWS Glue, Amazon S3, and Amazon Redshift. ETL is an acronym for Extract, Transform, and Load. It is an operation of pulling data from a source, cleaning or transforming it, and inserting it into a destination where it will be used. In such a scenario, the data is retained in Amazon S3. You process and transform it using AWS Glue. You then load the data into Amazon Redshift, a data warehouse used for analytics and reports.
The best thing about the template is that it does not reload everything each time. It reloads only the changed or the new ones. This is what they call an incremental load. It is time, money, and resource efficient.
Typically, when replicating data from storage into a data warehouse, most organizations reload the whole dataset every time. Even if barely, anything has changed, the system replicates all the work.
This template changes that. It is built to process only what is needed:
In simple terms, this template speeds up your data pipeline, makes it cheaper, and easier to maintain.
This is a blueprint for anyone working with data and would like to ensure that their warehouse is always current without wasting time or money.
It is beneficial if you are:
It is best to use the Incremental ETL Pipeline with AWS Glue template when your S3 data keeps changing, like hour by hour or day by day, and you would like Redshift to synchronize without reloading it all. It is also great when you wish to have a setup that is less maintenance and runs in a secure environment.
These are the components of this pipeline and what they accomplish in plain language:
All these components co-operate so that your pipeline flows smoothly and safely.
It is simple and quick to install this template in Cloudairy. Here's how:
After you do that, your pipeline is ready to execute. You can also collaborate with other Cloudairy coworkers to modify or extend the workflow.
This is a straightforward approach to creating an incremental ETL pipeline with AWS Glue. It reads the data from Amazon S3, transforms it, and writes it to Amazon Redshift without loading the entire thing every time. With serverless processing through AWS Glue, orchestration through Lambda, and monitoring through CloudWatch, this pipeline is simple to monitor and secure.
The Incremental ETL Pipeline with AWS Glue template is cost-effective and time-effective, and it maintains your data in an analytics-ready state. You can readily open and install this workflow in Cloudairy in a matter of steps, and it is a cost-effective measure for teams who don't want to put in extra effort to handle growing data. If you require an S3 to Redshift ETL pipeline, desire AWS Glue for incremental data loading, or are investigating serverless data integration and even AWS Glue alternatives, this template is a good place to start.
Find templates tailored to your specific needs. Whether you’re designing diagrams, planning projects, or brainstorming ideas, explore related templates to streamline your workflow and inspire creativity
Unlock AI-driven design and teamwork. Start your free trial today










Unlock AI-driven design and teamwork. Start your free trial today