WorkHub
- Home
-
Cloudairy Al
- Pricing
- Book a Demo
Whiteboard
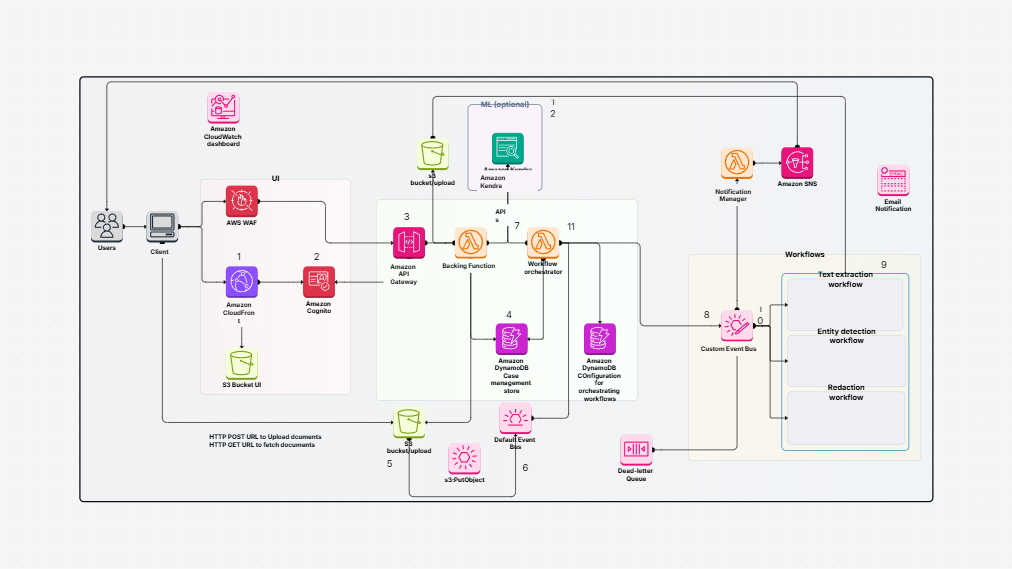
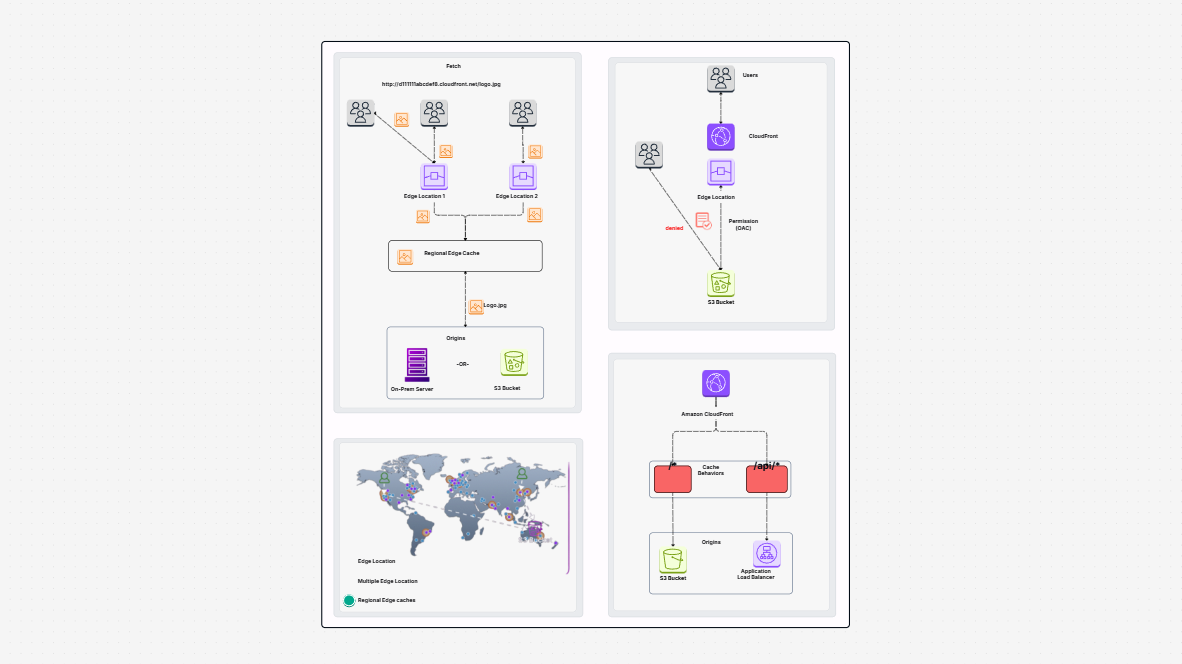
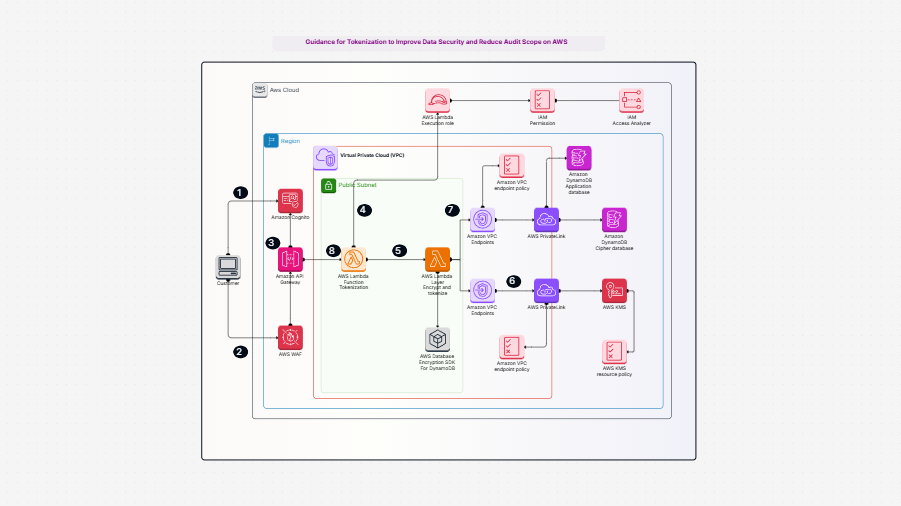
AWS 1 Did you ever wonder how businesses update their information daily without transferring everything repeatedly? Let's say you have an enormous bucket of storage containing thousands of files. You keep getting new files every day. Now, instead of copying the files every day, wouldn't it be more efficient to copy the new ones or the modified ones? That saves time and energy, doesn't it? This is the very problem this template solves.
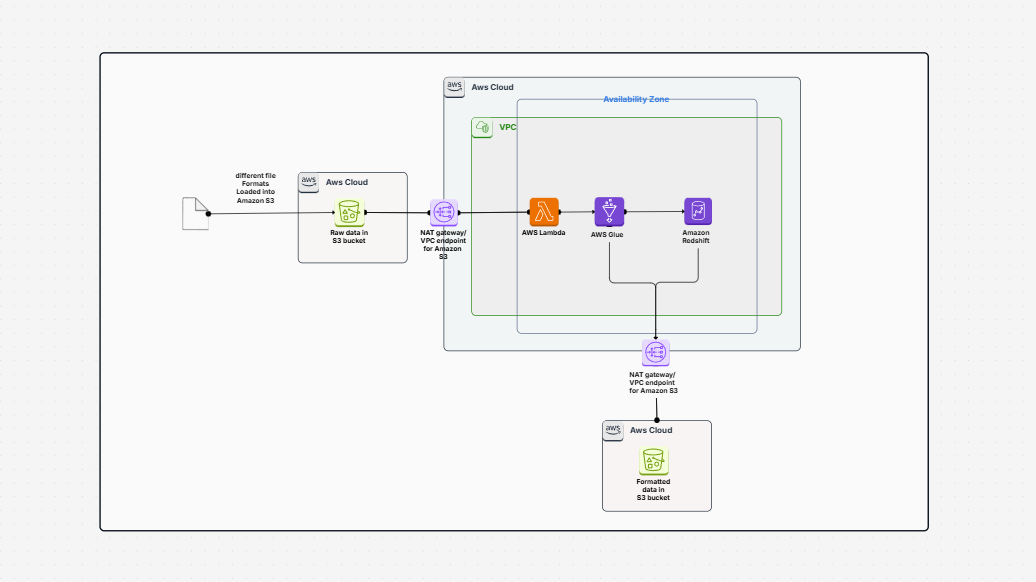
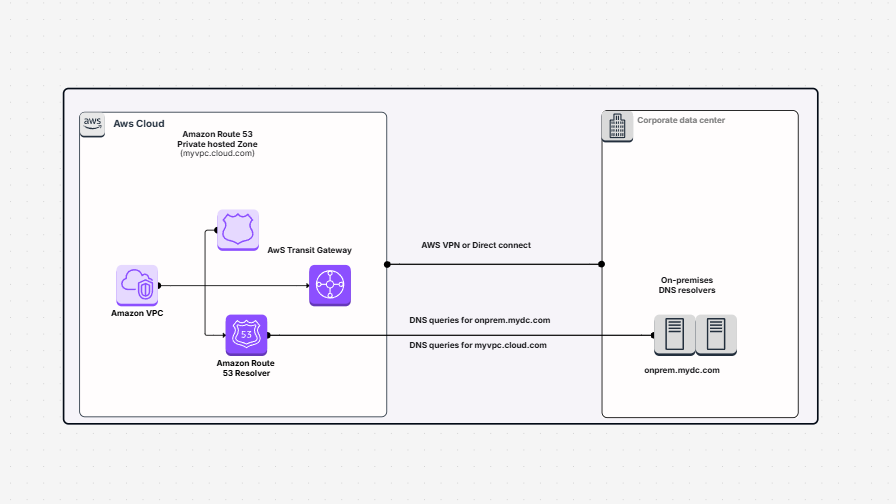
The Enhanced Document Understanding on AWS templates describes how you can build an incremental ETL pipeline with AWS Glue, Amazon S3, and Amazon Redshift.
In this pipeline, your data is stored in Amazon S3. You clean and process it using AWS Glue. Then you load it into Amazon Redshift, which is a data warehouse in which you can analyze or generate reports.
The best part? You don't have to reload everything every time. This pipeline loads only what is new or what has changed. This is referred to as an incremental load. It saves time, saves money, and consumes fewer resources.
Typically, when companies import data into the warehouse, they reload everything again every time even if only a handful of records have been updated. Think of repeating the same thing day in and day out. That's a waste of time and more expensive.
This template addresses that issue since it is designed to work with only what is required:
In short, this template gets your pipeline up and running. It is easier to manage, affordable, and gives you fresh data when you require it.
This template is ideal for anyone who has to re-enter their information without repeating the same procedures daily.
It is especially appropriate for:
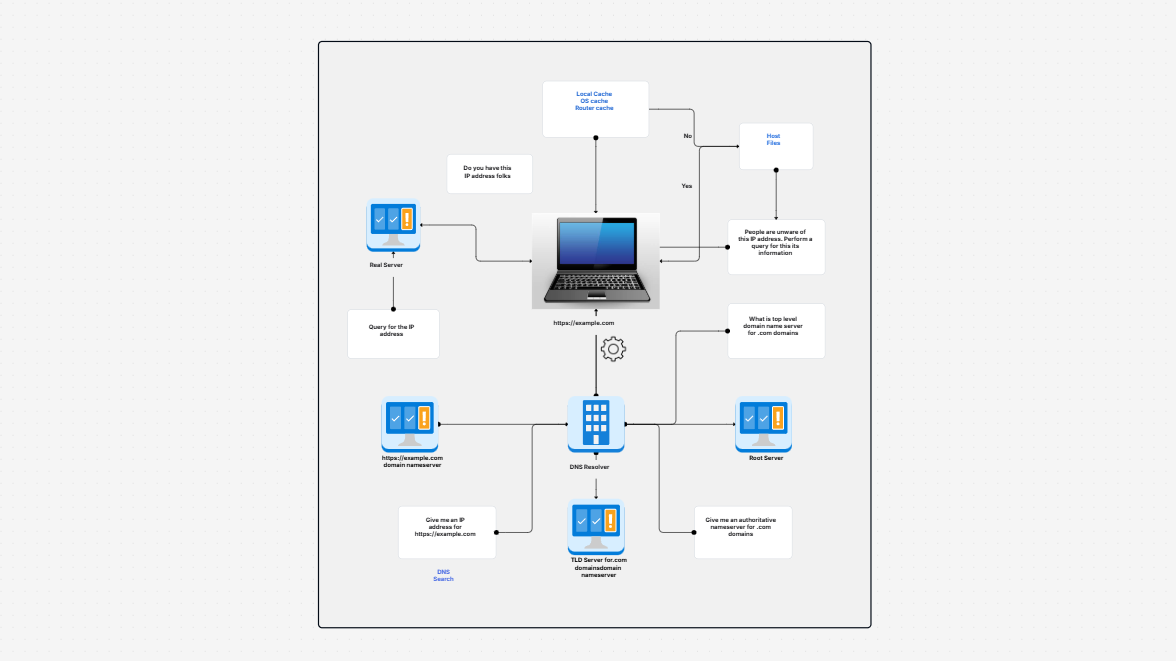
Here is what makes up the pipeline and what each segment does in easy terms:
All these parts function together, so your pipeline flows smoothly, safely, and without additional effort.
Installing this template to Cloudairy is quick and simple. Here is what you must do:
After you have completed all of this, your pipeline is ready to run. You can then modify or build upon it as your requirements for data increase.
This template provides you with a simple means of constructing an incremental ETL pipeline using AWS Glue, Amazon S3, and Amazon Redshift. It reads from S3, processes in Glue, and writes to Redshift without reloading the whole thing each time. With AWS Glue doing the processing, AWS Lambda handling triggers, and Amazon CloudWatch watching the pipeline, the setup is easy to handle and secure. It saves time and money and has your data ready for analytics. You can install and execute this workflow in Cloudairy in a few steps.
It is a good option for teams which should manage increasing data without performing additional work daily. If you need a solution to export S3 data to Redshift, require AWS Glue for incremental loading, or simply want to try serverless data integration, this template is an excellent starting point.
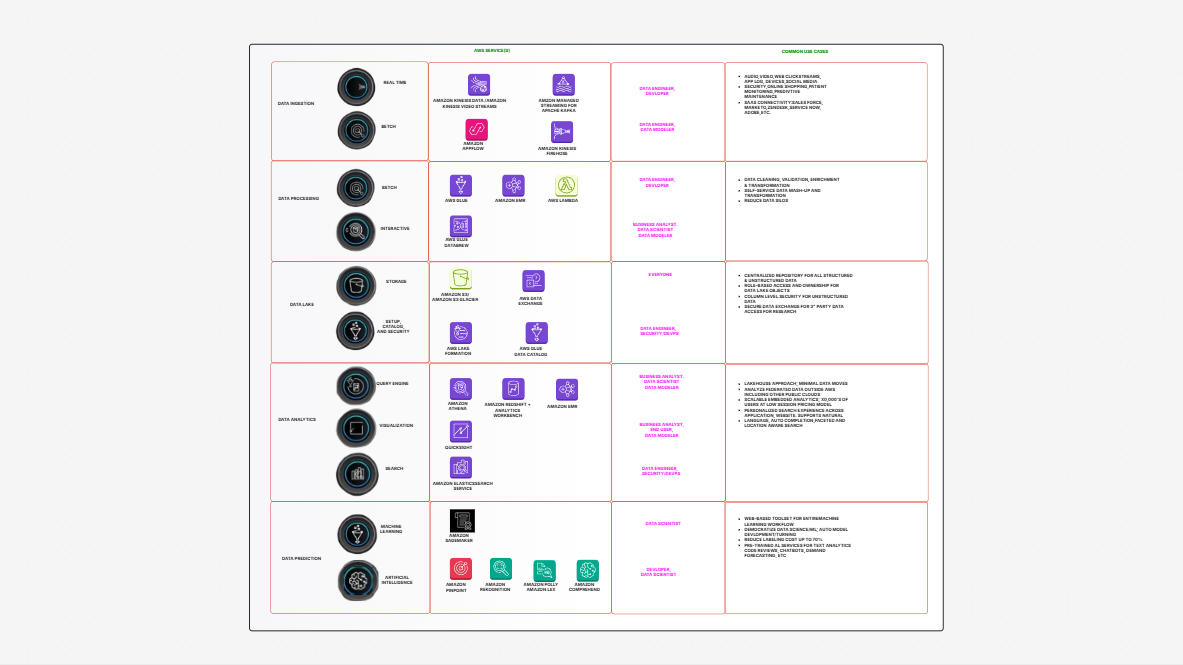
Find templates tailored to your specific needs. Whether you’re designing diagrams, planning projects, or brainstorming ideas, explore related templates to streamline your workflow and inspire creativity
Unlock AI-driven design and teamwork. Start your free trial today










Unlock AI-driven design and teamwork. Start your free trial today