Data Flow Pipeline Architecture Template

Cloudairy
AI Workspace for Diagrams & Collaboration
Get your team started in minutes
Sign up with your work email for seamless collaboration.
Whiteboard
Explore Data Flow Pipeline Architecture to streamline data processing, boost scalability, and enable seamless automation across your entire technology stack.
Explore Data Flow Pipeline Architecture to streamline data processing, boost scalability, and enable seamless automation across your entire technology stack.
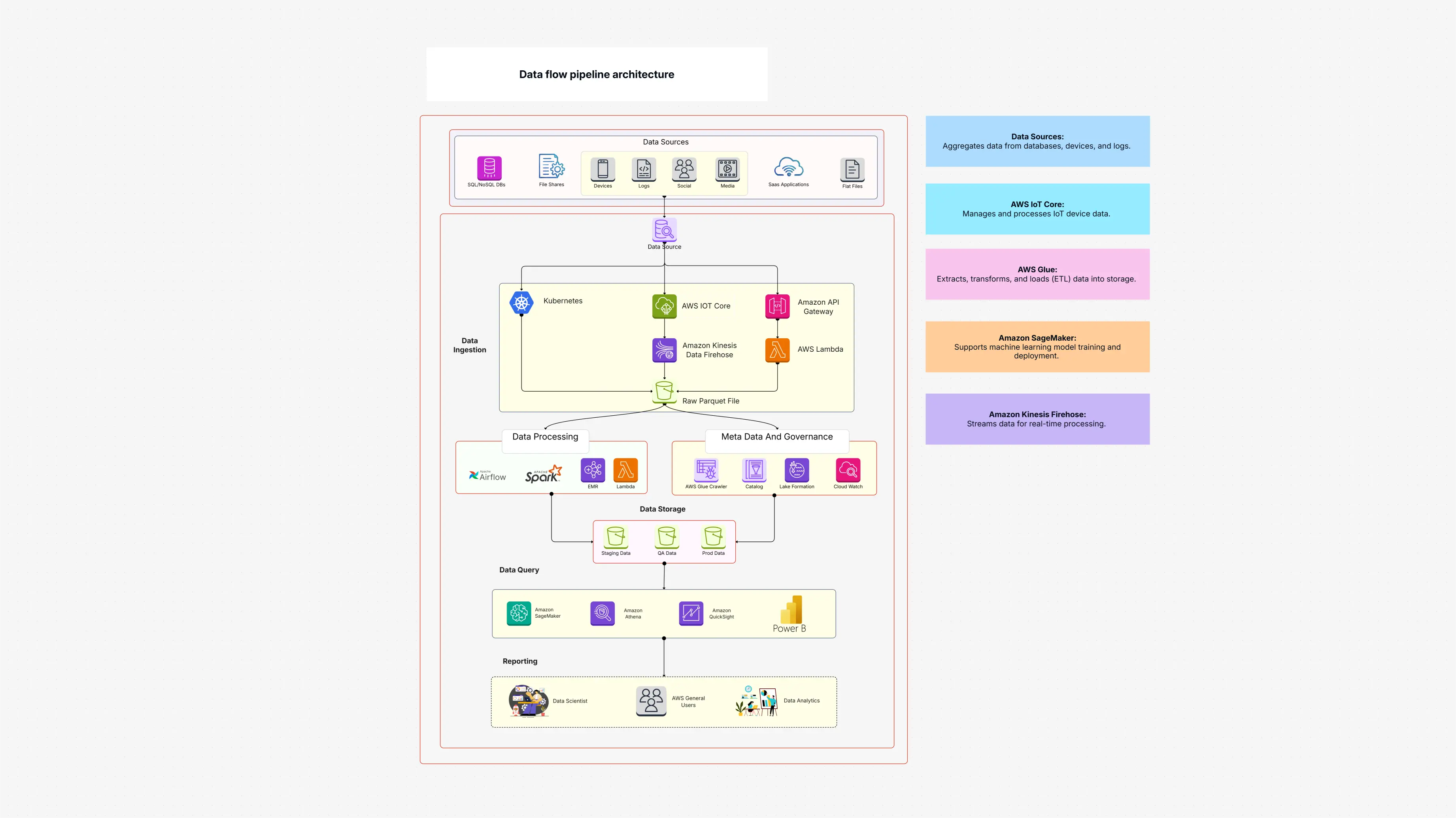
The Data Flow Pipeline Architecture template helps you move data from one place to another in a clean, safe, and easy way. It uses tools like Kubernetes, AWS Glue, Lambda, and Amazon S3 to handle real-time data and batch data.
This template lets you build a strong data pipeline that keeps collecting data, cleaning it, transforming it, and storing it with almost no manual work.
Powerful engines like Apache Spark and Apache Airflow help move the data to tools like Athena and Redshift, where you can run reports, do analysis, and ask questions.
It also includes helpful tools like AWS Glue Data Catalog, AWS Lake Formation, and Amazon QuickSight so you can see your data clearly and keep it well-governed.
Everything in this pipeline is connected, so your data flows smoothly from input to insight.
Building a safe and fast data pipeline can be hard, but this Data Flow Pipeline Architecture template makes it simple.
Here’s why it matters:
This ETL design helps you focus on getting value from your data, not dealing with confusion.
The Data Flow Pipeline Architecture template is useful for:
This template helps most when:
The Data Flow Pipeline Architecture includes:
Each component helps move your data safely from start to finish.
Starting with the Data Flow Pipeline Architecture template is simple:
The Data Flow Pipeline Architecture template helps you manage both real-time and batch data easily using cloud-native tools. AWS Glue, Kubernetes, Lambda, and S3 collect, clean, and analyze your data smoothly.
This template supports simple dashboards and advanced analytics, all while giving you strong governance, storage, and processing power.
Whether you’re new to cloud data or improving an existing system, this template gives you a strong foundation easy to grow, safe to use, and perfect for turning data into insights. Explore our Data Flow Architecture Diagram Template for more .
Loading subcategories...
 Manage all your work in one place
Manage all your work in one place
Collaborate with your team
Use Cloudairy for FREE—forever
Explore More