AWS
An Ultimate Guide to AWS Glue: Best Practices for Data Integration and ETL

AI Workspace for Diagrams & Collaboration
Get your team started in minutes
Sign up with your work email for seamless collaboration.
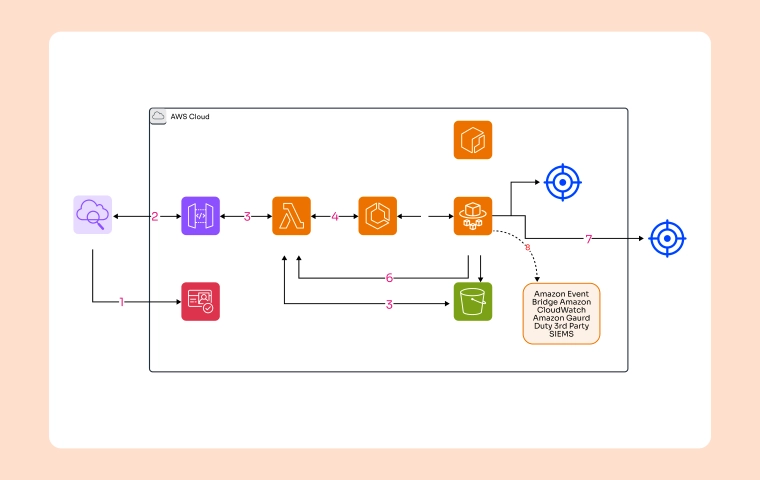
Modern businesses like ours often realize that a single cloud application can rely on a wide mix of microservices, various databases, and several trusted third-party APIs. Without careful and ongoing monitoring, maintaining steady performance and reliable availability quickly becomes a difficult challenge.Integrating monitoring directly into cloud architecture and cloud application architectures allows teams to oversee, manage, and improve systems well before issues arise. More than a routine responsibility, monitoring is vital for meeting compliance needs, sustaining user confidence, and protecting overall business continuity.
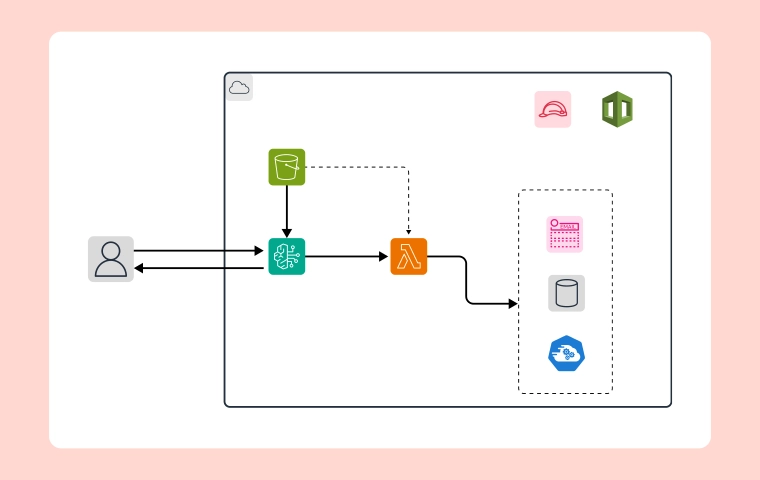
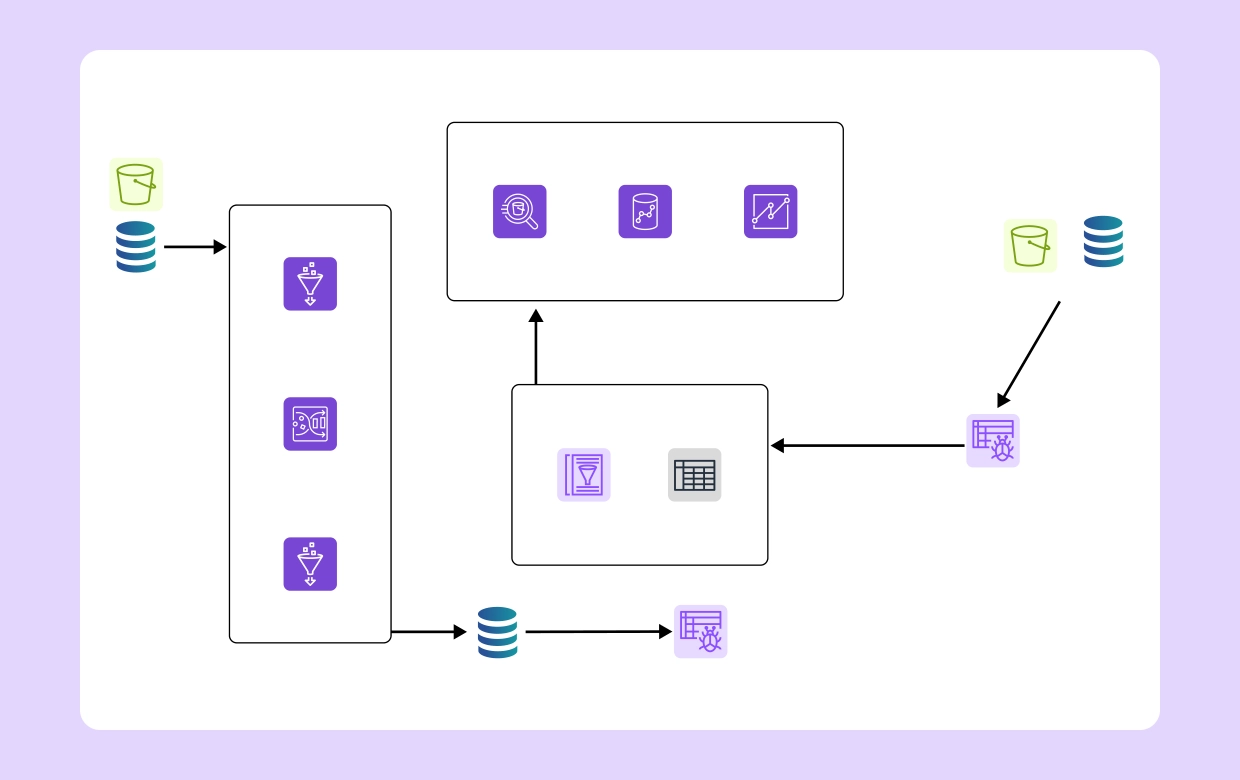
Storage is the foundation of every cloud workload. Failures or performance issues in storage can cascade into application outages. Advanced monitoring consistently provides clear visibility into storage health and overall efficiency.
.webp)
Applications often involve multiple dependencies that must be tracked in real time. Advanced monitoring ensures end-to-end visibility.
Cloud System Architecture Template
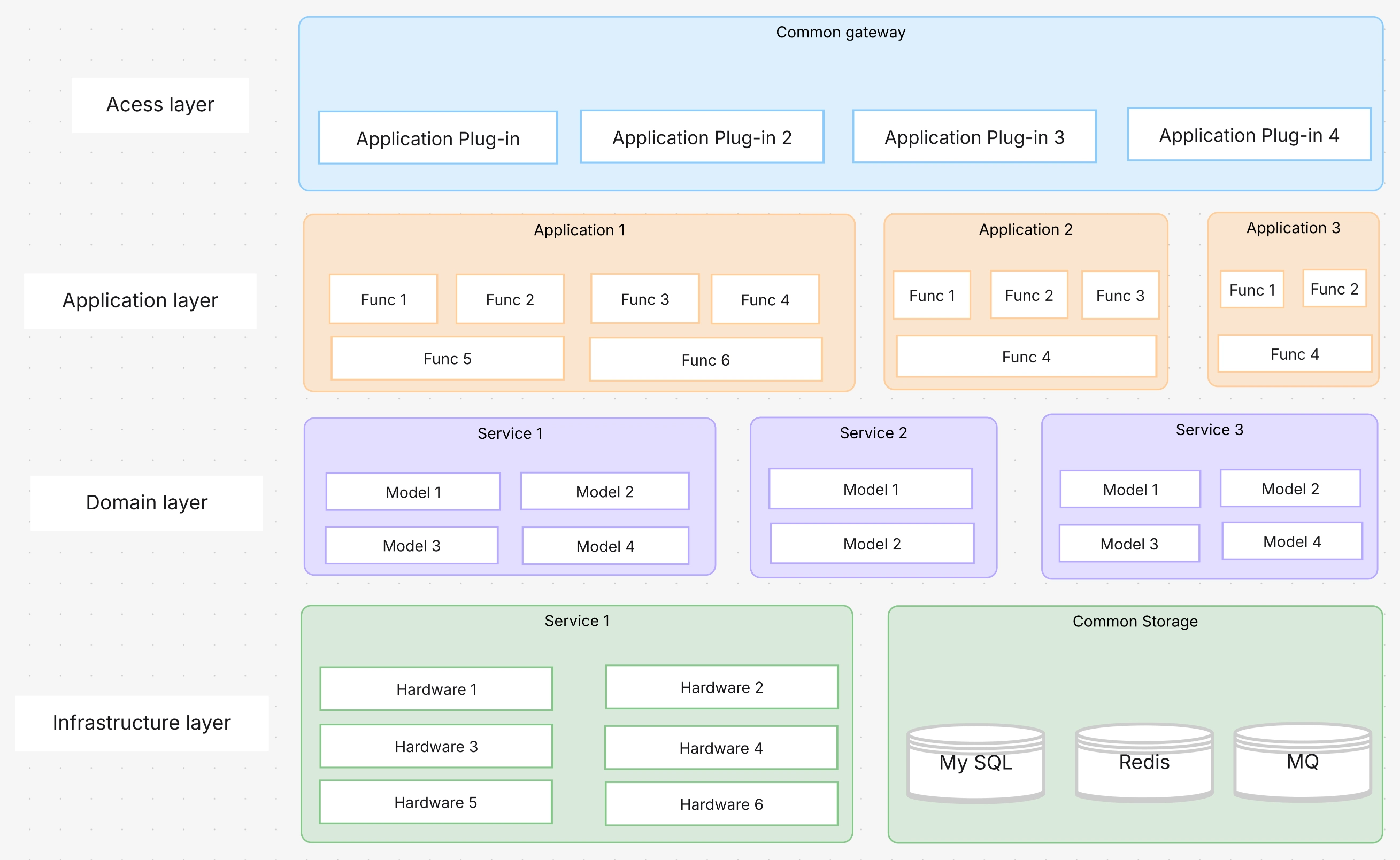
From my own viewpoint, the choice of monitoring tools really influences whether our teams detect issues early or unfortunately miss them. Advanced monitoring usually blends provider-native tools, dependable third-party APMs, and meaningful AI-powered insights.
While monitoring absolutely helps, it also brings along certain challenges that every forward-looking business needs to manage.
Monitoring cloud systems is the nervous system of modern cloud application architectures.It carefully connects storage, applications, and essential services, allowing organizations like ours to stay proactive instead of reactive. By embedding smart observability directly into both modern cloud storage architecture and flexible cloud application architectures, businesses can improve overall reliability, reduce downtime issues, and easily meet compliance standards. Cloudairy’s practical Cloud Architecture Diagram Tool enables teams to design monitoring-ready systems, ensuring observability remains a built-in feature and never just an afterthought.
Start using Cloudairy to design diagrams, documents, and workflows instantly. Harness AI to brainstorm, plan, and build—all in one platform.
Table of Contents

Introduction
 Manage all your work in one placeCollaborate with your teamUse Cloudairy for FREE—forever
Manage all your work in one placeCollaborate with your teamUse Cloudairy for FREE—forever


 Related Articles
Related Articles